
Boston Dynamics連携により計器読み取り機能を強化
1
会員(無料)になると、いいね!でマイページに保存できます。
共有する
米Google DeepMindは2026年4月14日、ロボット向けの新たな視覚言語モデル「Gemini Robotics-ER 1.6」を発表した。空間推論やタスクの成功判定能力を向上させたほか、米Boston Dynamicsとの連携により、複雑な工業用計器の読み取り機能を新たに実装した。本モデルはGemini APIおよびGoogle AI Studioを通じて開発者向けに提供される。

(画像:ビジネス+IT)
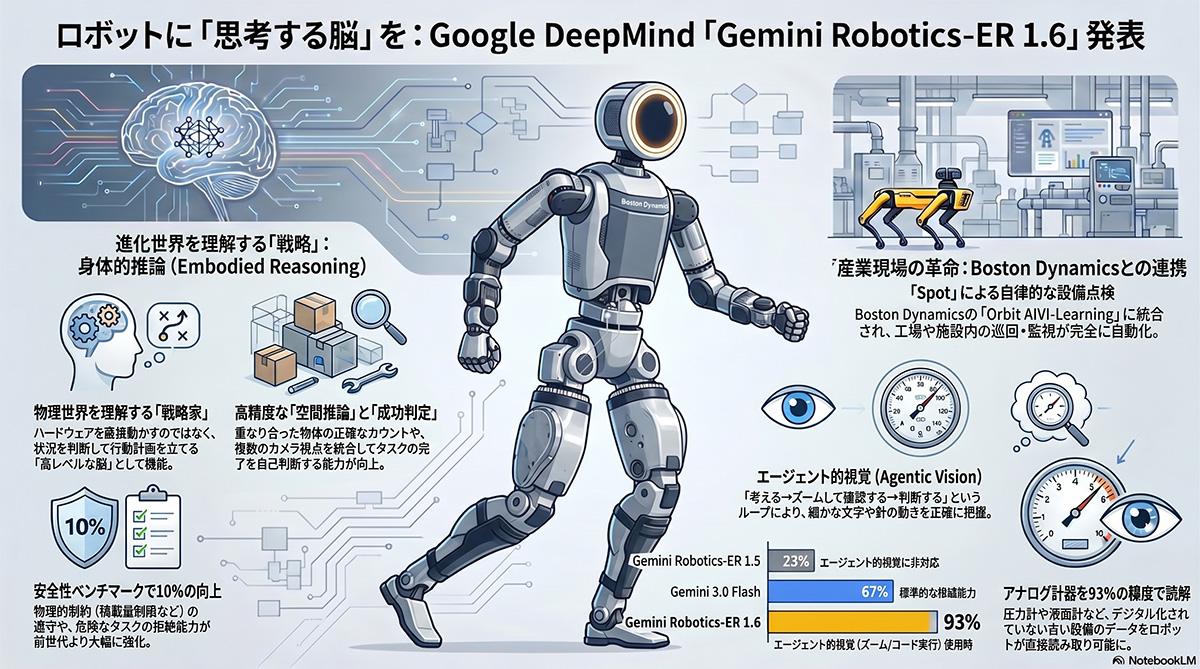
Google DeepMindが開発した「Gemini Robotics-ER 1.6」は、Gemini 3.0アーキテクチャのマルチモーダル処理能力を基盤とし、物理世界での推論に特化した視覚言語モデル(VLM)である。従来のロボットシステムが課題としていた視覚データの物理的論理への変換精度を向上させ、自律型物理エージェントの認知層として機能する。
本モデルの機能向上は、空間論理、マルチビュー理解、タスク計画、成功判定の領域にわたる。空間論理においては、物体の向きや環境の制約を考慮したポインティングと動作推論を実行する。マルチビュー理解では、複数のカメラからの映像ストリームを統合して状況を把握し、タスクの進行状況を推定する。
作業工程においては複雑なタスクを管理可能な手順に分割し、環境変化に応じた再試行などの判断を下す。加えて、ロボットが意図した動作(引き出しを開けるなど)を完了したか物理的な結果から検証する成功判定機能を組み込み、予測困難な環境下での自律稼働の信頼性を高めた。
【図版付き記事はこちら】Google DeepMind ロボティクスAIモデル「Gemini Robotics-ER 1.6」発表(図版:ビジネス+IT)
本モデルに導入された「Agentic Vision」機能は、視覚的推論とPythonコードの実行を連動させる技術である。この技術を活用し、Boston Dynamicsとの共同開発を通じて工業環境における高度な計器読み取り機能を実現した。円形圧力計、垂直レベルインジケーター、デジタル表示器などの多様な計器に対応する。
具体的には、針の位置、液面、容器の境界、目盛りなどの視覚情報を同時に認識し、それらの関係性を解析する。カメラの視点による歪みを補正してサイトグラス内の液体量を推定するほか、計器に印字された単位テキストを読み取り、桁数の異なる複数の針の指示値を統合して最終的な数値を算出する。
同モデルは、産業用の四足歩行ロボットからヒューマノイドまで幅広いハードウェアへの実装を想定しており、視覚的判断を伴う物理タスクの完全自動化に向けた基盤技術として提供される。
評価する
いいね!でぜひ著者を応援してください
会員(無料)になると、いいね!でマイページに保存できます。
ロボティクスのおすすめコンテンツ
関連タグ