

Google DeepMindは3日、マルチモーダルAIモデル「Gemma 4 12B」を発表した。ノートPC上で動作するエージェント型マルチモーダルAIを想定したモデルで、16GBのVRAMまたはユニファイドメモリーでローカル実行できる。Apache 2.0ライセンスで提供されるオープンモデルで、開発者はHugging FaceとKaggleから事前学習済みモデルとinstruction-tuned checkpointsをダウンロードできる。
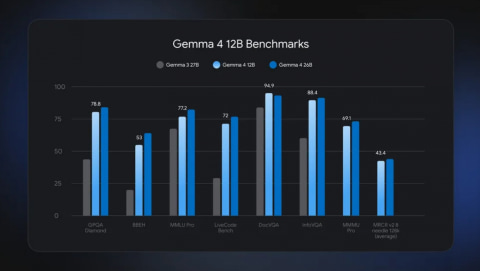
Gemma 4 12Bは、エッジ向けのE4Bと、より高度な26B Mixture of Experts(MoE)モデルの間に位置付けられる。26B MoEモデルの半分未満のメモリーフットプリントで、同モデルに近いベンチマーク性能を持つとしている。Gemma 4シリーズでは初の中規模ネイティブ音声入力対応モデルとなり、画像、音声、テキストを扱うエージェント型ワークフローへの利用を想定する。
特徴は、画像や音声の入力に個別のマルチモーダルエンコーダを使わない統合アーキテクチャ。従来のマルチモーダルモデルでは、画像や音声を言語モデルに渡す前に、別のエンコーダで変換する構成が一般的だった。Gemma 4 12Bでは、この分割された構成が遅延やメモリー使用量の増加につながるとして、音声と画像の入力をLLMバックボーンに直接統合する設計を採用した。
画像入力では、Gemma 4のビジョンエンコーダを軽量な埋め込みモジュールに置き換えた。同モジュールは単一の行列乗算、位置埋め込み、正規化で構成され、画像処理をLLMバックボーン側で担う。音声入力では、音声エンコーダを取り除き、生の音声信号をテキストトークンと同じ次元空間へ投影する。これにより、画像や音声をより直接的にモデルへ取り込めるようにした。
低遅延化に向けた仕組みとして、Multi-Token Prediction(MTP) draftersも備える。Google DeepMindは、これらの機能により、速度や推論能力を維持しながら、日常的なハードウェアで高度なマルチモーダル機能を利用できるとしている。
利用環境としては、LM Studio、Ollama、Google AI Edge Gallery App、Google AI Edge Eloquent app、LiteRT-LM CLIで試用できる。Google AI Edge Eloquent appでは、Gemma 4 12Bが音声入力の文字起こし、整形、翻訳をオフラインで行なうデモも示されている。開発ツールは、Hugging Face Transformers、llama.cpp、MLX、SGLang、vLLMでのローカル推論に対応する。