
Datadog Japanは6月2日、「2026年版 AI Engineering調査レポート」に関する報道機関向けの説明会を開催した。同レポートは6月1日付で米国で発表されたもの。主な調査結果として、「マルチモデル利用が標準に」「エージェントフレームワークの利用が前年比で倍増」「AIモデルへ送信されるデータ量も増加」の3点が指摘されている。

Datadog Japan Director of Solutions Engineering 守屋賢一氏
概要説明を行った同社のDirector of Solutions Engineeringの守屋賢一氏は「最近は、単にAIを使ってみるという段階から、どう本番環境で運用していくのかというフェーズに移り始めている」と指摘し、「マルチモデル化、エージェント型のワークフロー、外部ツール連携、データの増加などによって、AIシステム全体が急速に複雑化している」と語った。
同氏は、生成AIの利用率や効果創出に関して米国、ドイツ、中国といった主要国と比べると大きな差がある状況だとした上で、日本企業の課題を「生成AIを導入するところから、導入したAIをどう管理して効果を測定し、安全に拡張していくのかというフェーズに移りつつある」とした。

Datadog Japan Senior Developer Advocate 萩野たいじ氏
続いて、同社のSenior Developer Advocateの萩野たいじ氏がレポートの詳細説明を行った。同レポートは「1000社を超えるDatadogのお客さまから収集した大規模言語モデル(LLM)テレメトリデータに基づき、本番環境におけるAIエンジニアリングの現状を分析」したものだという。ユーザー企業の同意を得て、実データに匿名化処理や統計処理を行った上で活用しているものだが、具体的にどのようなデータを利用したのかといった詳細情報に関しては非公表となっている。
調査によると、7つの傾向が明らかになった。まず、複数のモデルに依存する組織が増えている点が挙げられる。また、新旧モデルの併存により、LLMに関する技術的負債が拡大している。さらに、エージェントフレームワークの導入拡大に伴い、詳細なテレメトリの重要性が高まっている。
加えて、大規模なシステムプロンプトを前提としたエージェント設計が進む一方で、プロンプトキャッシュの活用は十分とは言えない。コンテキストウィンドウの拡大により、設計の自由度は大きく広がっている。
一方で、エージェントの信頼性は依然として課題であり、LLM呼び出しではレート制限エラーが最も一般的な失敗要因となっている。なお、エージェントの構成は依然としてモノリシック型が主流であるという。
萩野氏はこのうち「マルチモデル」「エージェントフレームワーク」「コンテキストエンジニアリング」の3点に絞って解説を行った。LLMに関しては、OpenAIの利用比率が減少する一方、AnthropicおよびGoogle Geminiが大きく伸びており、大半の組織がすでにマルチモデル化している。
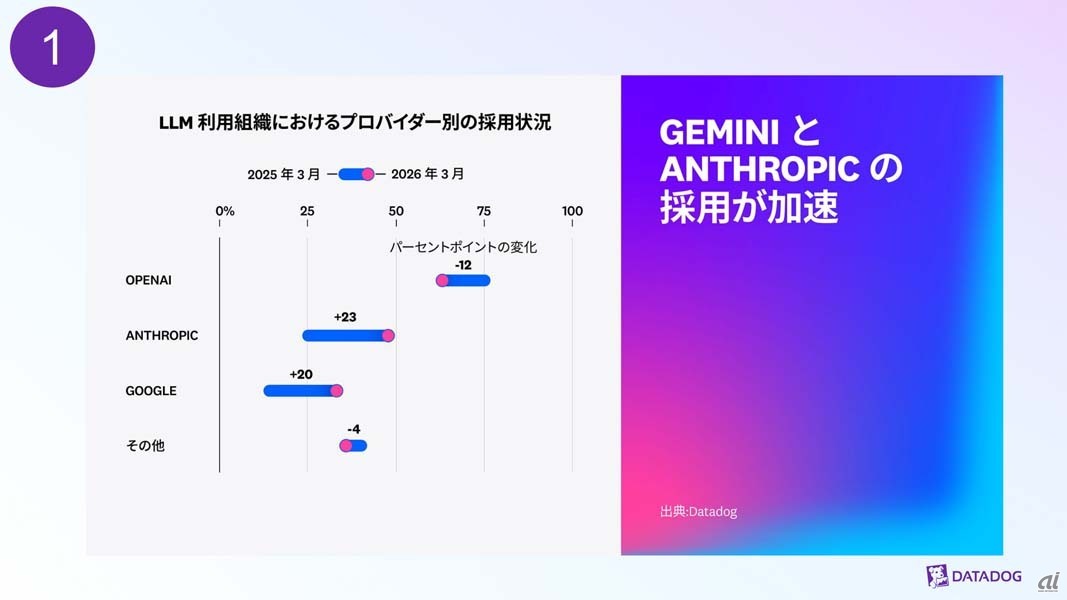
LLM利用組織におけるプロバイダー別の採用状況
1年前と比較して、6モデル以上を利用している組織の比率が2倍近くに増加しており、3モデル以上を利用している組織が70%を占める結果となった。また、エージェントフレームワークの採用率が過去1年間で倍増しており、リクエスト当たりのトークン使用料も2倍以上に増加しているという。
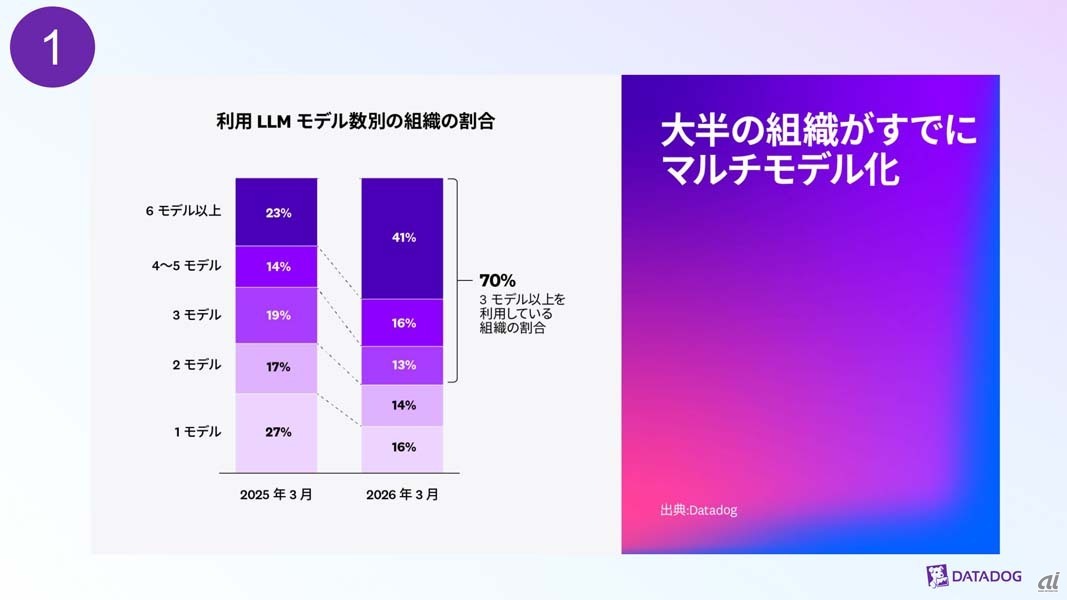
利用LLMモデル数別の組織の割合
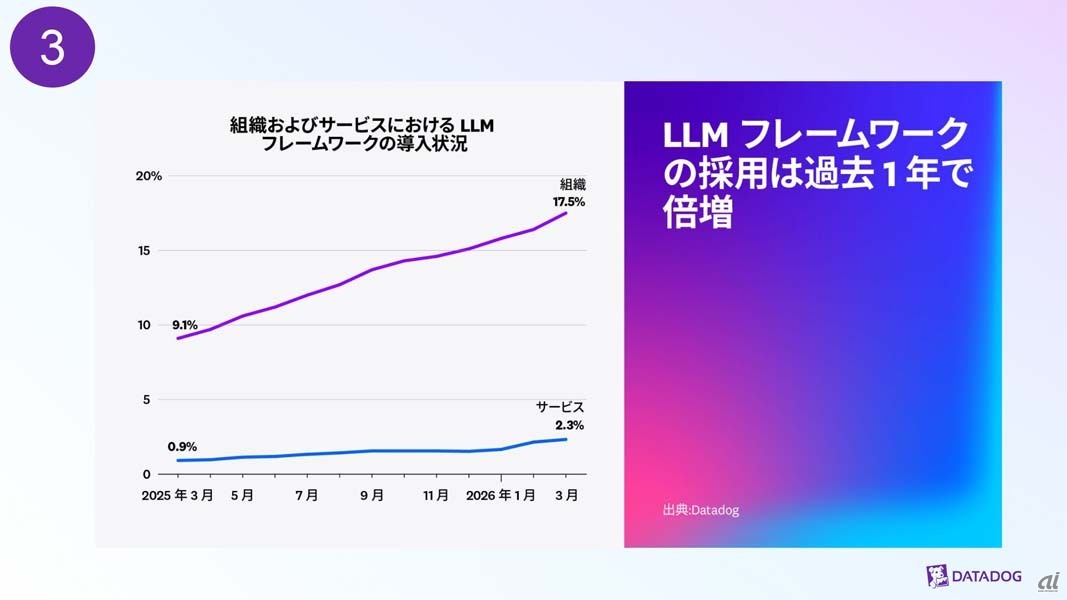
組織およびサービスにおけるLLMフレームワークの導入状況
こうした調査結果を踏まえて萩野氏は、企業が次に取り組むべきこととして「AIの利用状況、モデル、データ、コスト、パフォーマンスを可視化する」「AI活用が品質・効率・ビジネス成果につながっているかを測定する」「セキュリティと統制を担保しながら、本番運用・全社展開へ移行する」という3点を推奨した。
ZDNET Japan 記事を毎朝メールでまとめ読み(登録無料)