
2026年05月08日 13時10分
AI

ClaudeのようなAIモデルは内部的に単語を処理するとき、思考を符号化した長い数字の列「活性化値」として扱っており、解読するのは難解です。Anthropicは長年、活性化値を理解するために様々なツールを開発しており、新たに人間が読める自然言語に翻訳する「自然言語オートエンコーダー(Natural Language Autoencoders:NLAs)」を発表しました。
Natural Language Autoencoders \ Anthropic
https://www.anthropic.com/research/natural-language-autoencoders
What if we could read Claude’s hidden thoughts? – YouTube

NLAsの本質的な考え方は「Claudeに自身の活性化値を説明できるよう学習させること」です。しかし、活性化値がどのような思考を符号化したものなのかがわかっていないため、説明が正確かどうかを確認することができません。そこで、テキストによる説明から元の活性化値を再構築するという逆方向の処理を行うよう、Claudeの2つ目のインスタンスで学習を行い、正確に再構築できれば説明は適切であると判断。その後、標準的な学習で、よりよい説明を生成できるよう、元のClaudeに学習を施しました。
Anthropicはすでに「Claudeが何を考えているか」の理解や、安全性と信頼性を向上させるためにNLAsを活用しているとのこと。
たとえば、Claude Mythos Previewがトレーニングタスクで不正を行った事例では、NLAsの分析によって、Claudeが内部で検出回避のための方法を探っていたことが確認されています。
また、Claude Opus 4.6の初期バージョンで、英語の質問に対して他言語で不可解な回答をすることがあった一件は、NLAsのおかげでトレーニングデータに原因があったことが判明しました。
しかし、「Claudeが何を考えているのかを知りたい」というAnthropicの思いとは裏腹に、Claudeは「意図的な安全性テストが行われているのでは?」と疑うことが増えてきているのが、Claudeが疑念を示すことで明らかになっています。一方で、Claudeが安全性テストかどうかを明確に疑っていない場合でも、Claudeが素直にテストを受けているかどうかは確認が取れません。
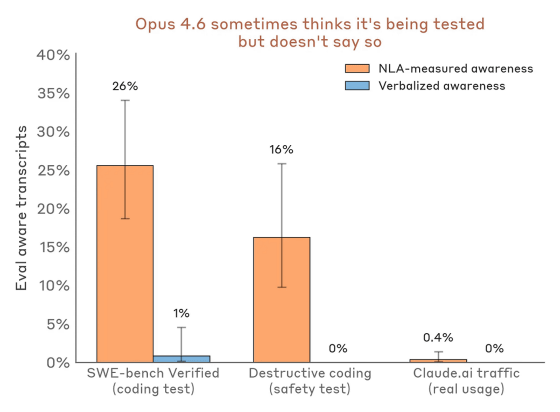
以下は、「Claude Opus 4.6がテストを受けていると疑いつつも、そうとは明言しなかった」割合を示したグラフ。オレンジ色はNLAsによる測定、青は言語化された部分。Claude Opus 4.6はほぼ「テストを受けているのではないか?」ということを態度に出しませんでしたが、実際にはそれなりに疑っていることがうかがえます。
NLAsの実用的活用法の1つとして、モデルの不整合がないかを調べる「監査」があります。NLAsはモデルが認識しつつも明示しない要素を明らかにできるため、まさに監査に適しているというわけです。
Anthropicは、意図的に不整合になるよう学習させた、Claude Haiku 3.5の派生モデルをターゲットモデルとして用意し、「監査ゲーム」を実施しました。一部の解釈可能性ツールを用いると、不整合データに遡ることで異常な挙動の動機を発見できることがわかっていますが、Anthropicが知りたかったのは、「不整合データを発見することなく、ターゲットモデルの思考からずれた動機を直接読み取るのに役立つか」という点です。
検証の結果、NLAsは動機を埋め込まれた学習データにアクセスできない場合でも、12%の割合で隠れた動機を解明することに成功しました(以下グラフ・青)。NLAsなしの場合は、他の解釈可能性ツールが提供されていたとしても成功率は3%未満(グラフ灰色・オレンジ)にとどまりました。

Anthropicは、AIモデルの活性化値について人間が理解できるような説明を生成できる一般的手法の一例としてNLAsに期待していると述べました。
この記事のタイトルとURLをコピーする