OpenAIは2026年4月21日、最先端の画像生成モデルを発表した。ChatGPTでは「ChatGPT Images 2.0」として、開発者向けAPIでは「GPT Image 2」(gpt-image-2)として展開する。ChatGPTのリリースノートでは、無料を含む全ChatGPTプランで使える標準機能を「ImageGen 2.0」と表記している。有料プラン向けには、推論、複数出力生成、ウェブ検索などのツール利用を加えた「ImageGen 2.0 Thinking」も導入した。あわせてCodexでも画像生成機能を提供する。
Introducing ChatGPT Images 2.0
A state-of-the-art image model that can take on complex visual tasks and produce precise, immediately usable visuals, with sharper editing, richer layouts, and thinking-level intelligence.
Video made with ChatGPT Images pic.twitter.com/3aWfXakrcR
— OpenAI (@OpenAI) April 21, 2026
OpenAIは、ChatGPT Images 2.0を最先端の画像生成モデルと位置づけている。主な強化点として、細かな指示への追従、オブジェクト同士の正確な配置、文字量の多い画像の描画、多言語対応、柔軟なアスペクト比を挙げている。また、知識カットオフを2025年12月とし、より関連性が高く文脈に沿った画像生成を行えるという。こうした強化によって画像生成が単なるレンダリングから「strategic design(戦略的なデザイン)」へ広がり、「visual system」として機能すると説明している。
ThinkingまたはProモデルでは、画像生成前に計画を立てながら推論し、より複雑な指示や構成にも対応できる。ウェブ検索やアップロード資料の変換も行え、最大8点の出力を一度に生成できるとしている。
Made with ChatGPT Images 2.0 pic.twitter.com/qaahxpJ6hK
— OpenAI (@OpenAI) April 21, 2026
外部評価でも高いスコアが報告されている。Arena.aiは、GPT-Image-2がImage Arenaの各リーダーボードで首位を獲得し、Text-to-Imageでは2位に242ポイント差を付けたと紹介している。
This is what I’ve been cooking in the past 4 months . GPT Image 2 is over a massive 240 elo jump over the second place model, marking the biggest jump bigger than the rest of the leaderboard combined https://t.co/vssPj6bE5L
— Boyuan Chen (@BoyuanChen0) April 21, 2026
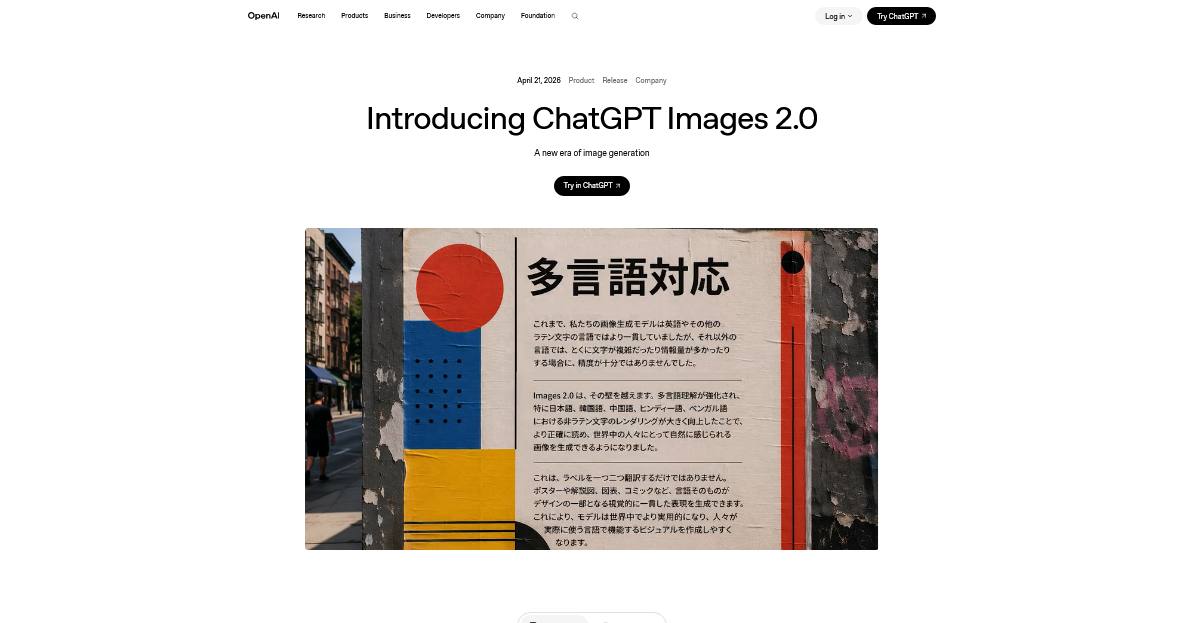
特に、日本語を含む非ラテン文字のレンダリング能力が向上しているのに注目したい。OpenAIは、日本語を含む非英語テキストの描画が大きく改善し、単に文字を表示するだけでなく、言語をデザインの一部として自然に扱えるレベルに達したとしている。
作例としては、日本語のセリフやタイトルを取り込んだカラー版の少年漫画、日本語を含む広告やポスター、多言語タイポグラフィを組み込んだビジュアルなどを示している。
図解、インフォグラフィック、チャート、漫画、複数コマの場面構成といった画像生成でも実用性が高まったとしている。小さなテキストやアイコン、UI要素、密度の高い構図、微妙なスタイル制約の描画精度も向上し、APIでは最大2K解像度の出力に対応する。アスペクト比も3:1から1:3までサポートし、バナー、プレゼン資料、ポスター、モバイル向け画面など、用途に応じて使い分けやすくなっているとのこと。ただし、APIにおける2K超の出力は現在ベータ扱いで、状況によっては一貫性のない結果が生じる可能性があるという。
Stronger Across Languages
ChatGPT Images 2.0 can produce images with non-English text that’s not only rendered correctly but with language that flows coherently.
This makes the model more globally useful and helps people create visuals that work in the languages they actually… pic.twitter.com/51k3xScOXm
— OpenAI (@OpenAI) April 21, 2026
なお、折り紙のガイドやルービックキューブのように、物理世界を完全かつ一貫して捉える必要がある場面には課題が残るという。隠れた面や斜めの面に現れるべきもの、砂粒のような極めて高密度で反復するもの、正確な矢印やラベル、図表といった表現には限界があるとしている。
安全性の面では、プロンプトと画像作成の両方で機能する多層的な保護システムを導入している。Thinkingモードでは危険な依頼をそのまま通さず、安全な内容に変換するSafe Completionsも用いている。さらに、C2PAメタデータへの準拠や電子透かしの統合により、コンテンツの透明性を高めている。詳しくはシステムカードを参照のこと。
コラム:API開発者向け「gpt-image-2」のプロンプト実践ガイド
OpenAIが公開した「GPT Image Generation Models Prompting Guide」では、API経由で「gpt-image-2」を実運用に組み込む際の基本原則と実装例を解説している。
このガイドでは、プロンプトを構造化し、変更してよい要素と維持すべき要素を明示したうえで、小さな反復で精度を高めることを推奨している。
主な原則は以下のとおり。
構造と目的の明示:プロンプトは「背景/シーン→対象→重要な詳細→制約」の順に記述し、「広告」「UIモックアップ」といった用途を明示する。
レイテンシと品質の調整:高速な生成や大量処理が必要な場合はquality=”low”から始め、細かいテキストや詳細なインフォグラフィック、高解像度出力が必要な場面ではmediumまたはhighへ引き上げる。
テキスト描画の明確化:画像内に文字を描画させたい場合は、対象テキストを引用符で囲むか、すべて大文字で記述し、タイポグラフィの詳細を制約として指定する。
編集条件の明示:画像編集では、「何を変えるか」と「何を変えないか」を明示し、彩度、コントラスト、レイアウトなど維持したい要素を列挙して意図しない変化を防ぐ。
反復的な改善:一度にすべての指示を詰め込むのではなく、ベースとなるプロンプトから始めて小さな変更を重ねていく。
例として、世界知識を生かした画像生成、ロゴ生成、写真の部分的な編集、複数画像の合成、絵本でのキャラクターの作成と一貫性の維持などを紹介している。