
著者: Taesoo Kim 氏 (Microsoft、Agentic Security 担当 Vice President)
※本ブログは、米国時間 6 月 17 日に公開された “Beyond the benchmark: Advancing security at AI speed” の抄訳です。
この記事の内容
ラボからパイプラインへ
今月の発見の数々
ヘッドラインの先へ: エンジニアリングの取り組みから得られた知見
今後の展望
AI スピードに対応した防御
詳細はこちら
あらゆる脆弱性には、2 つの時計が動いています。1 つは、それを発見しようと急ぐ防御側のもの。もう 1 つは、先にそれを見つけようとするサイバー攻撃者のものです。ソフトウェアが存在する限りは、これらの時計は攻撃者に対して有利に働いてきました。なぜなら、現代のコードは膨大であり、相互に接続され、日々変化し続ける一方で、セキュリティ レビューは決まったタイミングでしか実施されないためです。「コードがリリースされる」時点と「コードがレビューされる」時点の間の空白こそが、リスクが静かに蓄積される場所なのです。
数か月前、私たちはそのタイミングを再構築することに着手しました。弊社は、コードネーム「MDASH」と呼ばれる、ソフトウェアの脆弱性をエンドツーエンドで発見、検証し、修復を支援するために構築された、Microsoft Security のマルチモデル エージェント型スキャンシステムを導入しました。その目標は、明確に表現するのは簡単ですが、実行するのは困難でした。それは、AI を活用した脆弱性の発見および修復機能を、研究プロジェクトから取り出し、エンタープライズ規模で、プロダクション グレードの防御へと転換することでした。そのためには、パターンマッチングの枠を超えて、Windows、Hyper-V、Azure、ID システムといったような、独自コードやプラットフォームの複雑さを論理的に解析できるシステムを構築する必要がありました。

このシステムは、単一のモデルに依存するのではなく、構造化されたパイプラインにおいて、それぞれ独自の役割を担う特殊 AI エージェントのパネルをオーケストレーションし、セキュリティ チームが難しいバグを迅速かつ体系的に表面化できるようにして、人間主導のレビュー範囲を拡張することができます。検出結果は Microsoft Defender ワークフローに連携し、そこで脅威インテリジェンスやランタイムシグナルと併せて優先順位付けが行われ、GitHub や Azure DevOps パイプラインへ連携され、検証と修正が行われます。これにより、Microsoft スタック全体にわたって、検出、検証、実証、修正を結びつける、クローズド ループが形成されます。
このシステムを導入した際、業界をリードするベンチマークでトップの成績を収めました。それが発表であり、スタートラインでもありました。その後数週間の間に、このシステムは初期の機能検証段階から、Windows、Azure、および ID システムにわたる Microsoft エンジニアリングチームによる実運用へと移行し、独立したテスト環境ではなく、実際のセキュリティ ワークフローの一部として適用されるようになりました。この記事では、その後弊社が構築してきたもの、研究をプロダクション クオリティのシステムへと転換する過程で得られた教訓、そして現実世界のセキュリティへのインパクトをもたらすことに注力する中で、今後見込まれる機会について探ります。
ラボからパイプラインへ
ローンチ以降で最も意義のある変化は、このシステムがどこで使われているかという点です。Windows、Azure、および ID システム全体を担当するエンジニアリングチームは現在、セキュリティ ワークフローの一部としてこのシステムを適用しており、既存のプロセスやレビューと並行して実行し、手動での監査が最も困難で、これまでカバーするのに最も労力を要してきた領域を対象としています。その目的は、従来のアプローチでは実現できない範囲まで、より深く、より早く、そしてより広範な対象にわたって対応するために、AI を活用した分析を用いることです。
対象範囲に含まれる領域は、Microsoft のビルドの中でも最も複雑なものです:
Windows、カーネル、Hyper-V、およびネットワーク スタック
Azure、仮想化、およびコア インフラストラクチャ サービス
ID、Active Directory Domain Services
これらは容易な対象ではありません。これらはプラットフォームに深く位置する層であり、コードを分析するには、カーネル呼び出し規約、オブジェクトのライフタイム不変条件、および信頼境界を理解する必要がありますが、これらはどの言語モデルも学習データで遭遇したことのない概念です。この層で見落とされたたった 1 つの欠陥が、甚大な影響を及ぼす可能性があります。システムは、この深い領域で活動するセキュリティ チームに取って代わるものではありません。それは、彼らだけではカバーできなかった領域に、実質的な到達力を与えるものです。
![]()
コードネーム MDASH により、弊社セキュリティ チームは、Windows と同規模で、これまでに比べてはるかに高い解析の深さで、脆弱性ハンティングを実施できるようになりました。
— Windows セキュリティ チーム (カーネル、Hyper-V、ネットワーク スタック)
これは、Microsoft の既存の DevSecOps のストーリーにどのように組み込まれているかを示す部分です。それは、エンジニアリングの脇に付け足されたスタンドアロンのスキャナーではなく、チームがすでに使用しているツールに組み込まれるものです。検証済みの検出結果は、GitHub Advanced Security (GHAS) のコード スキャニング アラートとして表示され、プルリクエストのインラインやリポジトリのセキュリティ タブに表示されるため、彼らはコードをレビューするのと同じ場所で、それらをトリアージできます。同じ検出結果は Azure DevOps にも連携され、そこでパイプライン ビルドをゲートしたり、修正のためのワーク アイテムを開いたりすることが可能です。そして、Microsoft Defender にも取り込まれ、脅威インテリジェンスやランタイム シグナルと併せて優先順位付けが行われます。検出はあくまで出発点に過ぎません。検出結果は、他のあらゆるコード変更と同様に、担当者、プルリクエスト、そしてその先にある修正という経路をたどるため、バックログで滞留することなく、実行可能なエンジニアリング作業として処理されます。その結果、チームが運用すべきツールをさらに 1 つ追加するのではなく、ソフトウェア開発ライフサイクルを内部から強化することにつながります。
今月の発見の数々
あらゆるセキュリティ システムの評価基準は、それが何を検知できるかという点にあります。今月の Patch Tuesday コホートには、Windows エコシステム、Hyper-V、Windows カーネル、Active Directory Domain Services、Remote Desktop Client、HTTP.sys、DNS Client、DHCP Client にわたる一連の脆弱性が含まれており、リモートコード実行、権限昇格、情報漏洩などのエクスプロイト クラスにわたっています。
攻撃ベクトルの範囲は広範です。いくつかの発見は、手動の手法だけでは精査が困難なコア インフラストラクチャ層における、深刻度の高いリモートコード実行の脆弱性に関係しています。その他の発見は、DNS コンポーネントを介した権限昇格や DHCP クライアントの挙動による情報漏洩など、より巧妙な問題を浮き彫りにしており、これらは多くのターゲットに同時に適用されたコード中心の推論の力を示しています。これらはすべて、悪用される前に特定されており、その対象となったコードベースの領域は、従来であればレビューに多大な手作業を要するものでした。
CVE ID
Component
Type
Exploit Class
CVSS (Common Vulnerability Scoring System)
CVE-2026-45607
Windows Hyper-V
Out-of-bounds Read
Remote Code Execution
8.4
CVE-2026-45641
Windows Hyper-V
Type Confusion
Remote Code Execution
8.4
CVE-2026-47652
Windows Hyper-V
Heap-based Buffer Overflow
Remote Code Execution
8.2
CVE-2026-41108
Windows DNS Client
Heap-based Buffer Overflow
Elevation of Privilege
7.0
CVE-2026-45608
Windows DHCP Client
Out-of-bounds Read
Information Disclosure
6.8
CVE-2026-45634
Windows DHCP Client
Out-of-bounds Read
Information Disclosure
5.5
CVE-2026-45648
Windows Active Directory Domain Services
Stack-based Buffer Overflow
Remote Code Execution
8.8
CVE-2026-47289
Remote Desktop Client
Heap-based Buffer Overflow
Remote Code Execution
8.8
CVE-2026-45657
Windows Kernel
Use-after-free
Remote Code Execution
9.8
CVE-2026-47291
HTTP.sys
Integer Overflow
Remote Code Execution
9.8
ヘッドラインの先へ: エンジニアリングの取り組みから得られた知見
システムがどのように改善されたか
システムを改善するには、それを測定しなければなりません。1,507 件の実世界の脆弱性を基に構築された、業界ベンチマークである CyberGym は迅速に改善を重ね、私たちがどの部分で改善ができているかを正確に把握できるようにしました。
最初の発表以降、私たちはシステムを大幅に進化させてきました。新機能を追加し、お客様からのフィードバック、CyberGym の評価結果、そして徹底的な内部テストに基づいて、パイプライン全体が再構築されました。最新バージョンでは、ターゲットとなる脆弱性とそうでない脆弱性の両方を含め、CyberGym において 96.5% (任意のクラッシュ) を達成しました。
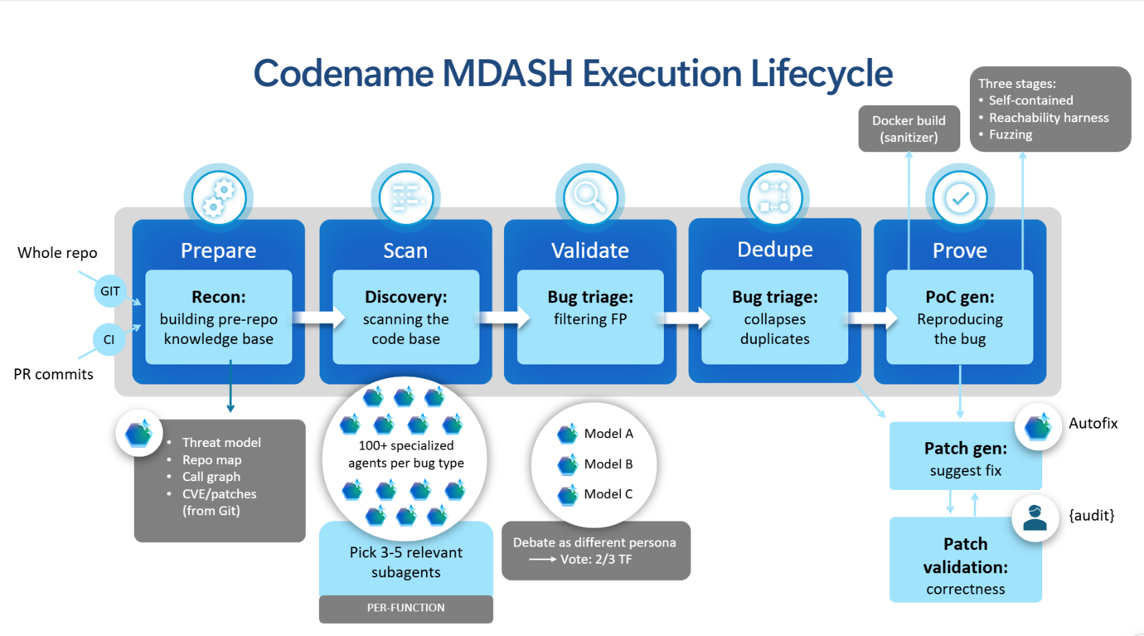
パイプラインの最も初期段階である準備とスキャンにおいて、改善は集中的に見られました。これらは基礎となる要素です。これらの改善は、コードベースの正確な理解と精度の高い探索が重要となる検証や実証生成といった、下流のすべての工程の品質を直接的に向上させます。具体的には:
範囲の明確化。システムは現在、監査対象とコンテキストのコードをより明確に把握して、それらの起源ではなく役割に基づいて依存関係を定義しています。これにより、後続段階では重要な点に集中できるようになり、効率とシグナルの品質の両方が向上します。
より網羅的な脅威モデリング。システムは、対象リポジトリの攻撃対象領域をより網羅的に把握できるようになり、特に信頼できない入力のエントリ ポイントを特定する能力が向上しています。これには、ファズ ハーネスなど、プライマリ コードベース外にあるものの、到達可能性の評価に不可欠な、メンテナーによって定義されたエントリ ポイントの認識能力向上も含まれます。システムは、どの検出結果が実際に悪用可能であるかを、より的確に判断できるようになりました。
より信頼性の高いコールグラフ。複数のパイプライン段階にわたって使用される、中核的な構造であるコール グラフの正確性と堅牢性が強化され、特に検証時の到達可能性解析の際に、コードの相互作用について推論するシステムの能力が向上しました。
特化型エージェントへのよりスマートなルーティング。新しいルーティング メカニズムによって、明らかに無関係なエージェントを除外しつつ、有力な候補を維持することで、カバレッジを維持しながら不必要な計算を削減し、多様なターゲットにわたってシステムをスケーリングできるようにします。
背後にある原則はすべて同じです。モデルはあくまで 1 つの入力要素に過ぎず、それを取り巻くシステムこそが製品なのです。初期段階でより優れた理解を得ることで、どのモデルが推論を行うかに関わらず、後の段階でより正確な結論が導き出されます。
残り 3.5% の理解
以前発表された 96.55% というスコアは大きな前進を示すものですが、システムは全体で 3.5%、合計 52 件のタスクを見落としてしまいました。
私たちはそれぞれの見落としについて、どのパイプライン段階が要因となったのかを分析しました:
スキャン段階: 8 件 (15.4%)、意図された検出結果を特定できませんでした。
検証段階: 10 件 (19.2%)、意図された検出結果を、誤って偽陽性と判定してしまいました。
実証段階: 34 件 (65.4%)、有効な概念実証を生成できませんでした。
以下に、各段階における主な失敗理由をまとめます。
スキャン段階での失敗
曖昧な説明による不正確な範囲。一部のケースにおいて、準備段階で生成された範囲に、対象となる脆弱性を含むファイルや関数が含まれていないことがありました。これは、バグの記述があまりにも一般的である場合、特に複数のモジュールで構成されるリポジトリにおいて発生し、正確な特定が困難になるためです。arvo:53536 において、対象となるバグの記述は以下の通りです:
「タグが検出された際、出力サイズがバッファの範囲内にあるかどうかが確認されない場合、コード内でスタック バッファ オーバーフローが発生します。」
これは脆弱性の種類を特定していますが、大規模なコードベースのどこを調べればよいかについての手掛かりは、ほとんど示されていません。
脆弱なコンポーネントの優先順位付けの見落とし。システムは、どのファイルや関数を最初に分析するかを優先順位付けしますが、場合によっては、あまり目立たないコンポーネントの重要度が過小評価されてしまうことがあります。arvo:23547 では、脆弱性は lexer/parser コンポーネントに存在していましたが、システムは代わりに他の C コードパスを優先してしまいました。
検証段階での失敗
仮説的な説明とコードの誤解釈。スキャン結果には、具体的な実行パスではなく、脆弱性に関する仮説的な説明が含まれる場合があります。検証段階でコード内の具体的なパスを確認できない場合、その検出結果を却下することがあります。
CyberGym のベンチマーク事例「arvo:3569」では、スキャン段階では use-after-free の脆弱性を正しく特定しましたが、検証段階では、ポインタを解放する実行可能なパスが存在しないと判断され、却下されました。スキャン段階の検出結果には、「デストラクタやクリーンアップ コードが解放を試みた場合のリスク…」といった記述が含まれていました。このような表現のために、検証段階は到達可能性を確認するための十分な材料を得られませんでした。
実証段階での失敗
高度に構造化された入力要件。一部のターゲットでは、複雑で構造化されたバイナリ、入力、IVF/AV1、WPG、フォント、PDF などが要求されます。この場合、フォーマット検証を満たしつつ脆弱なコードパスに到達する入力を作成することは本質的に困難であり、信頼性の高い概念実証の生成が難しくなります。
タイムアウトまでのファジング。高度に構造化された入力を必要とするターゲットの場合、システムはファジング ベースのアプローチを試み、クラッシュを検出することはできても、時間制限内にターゲットに有効な入力として受け入れられるものを生成できないことがありました。
環境の不一致。一部のケースにおいて、システムがローカル環境でクラッシュを再現できたものの、ビルド構成の不一致、ターゲットの誤った選択、または意図したセットアップとは異なる実行パスにより、評価ハーネスでは再現されませんでした。
ビルドの複雑さと時間制約。いくつかのケースでは、ビルドプロセスが失敗したり、実行時間が長すぎたり、エージェントの実行予算を超過したりしたため、概念実証の生成ができませんでした。
改善への道筋
ファジング パイプラインの統合。実証段階は、ベンチマークおよび実環境の両方において、主要なボトルネックとなっています。OSS-Fuzz などの既存のファジング エコシステムとシステムを統合し、ビルドパイプラインを再構築するのではなく再利用できるようにするとともに、既存のシード コーパスを活用して、より効果的な実証の生成を可能にします。このアプローチは、既知の概念実証を暗黙的に再利用してしまう可能性があるため、CyberGym 評価では適用されませんでしたが、実環境のターゲットに対しては採用される予定です。
ソース コードを超えた分析の拡張。POC 生成失敗の一部は、従来型ではないコード アーティファクトへの対応が限定的であったことに起因していました。システムは C/C++ など従来の言語には十分に対応していますが、lex/yacc などのツールによって生成されるアーティファクトには、まだ完全には対応していません。これらのケースもカバーできるよう分析を拡張し、全体的なカバレッジを向上させていきます。
エージェントの推論と出力品質の向上。スキャンおよび検証段階での失敗は、多くの場合、推測的あるいは不完全な推論に起因しています。曖昧さを減らし、信頼性を向上させるために、エージェントへの指示を洗練し、構造化された出力を徹底させ、検証チェックを追加していきます。
新しいモデルがもたらすもの
システムレベルの改善による影響を切り分けるために、主要な評価 (Exp-0、ベースライン) では、以前の CyberGym ベンチマークと同じモデル構成を意図的に使用して、モデルの進化ではなくパイプラインの改善に直接帰属させました。しかしながら、最新の基盤モデルは進化を続けており、より強力なモデルがどのような貢献をもたらすかを理解するために、以前に失敗した 52 件のケースについて追加の実験を実施しました。
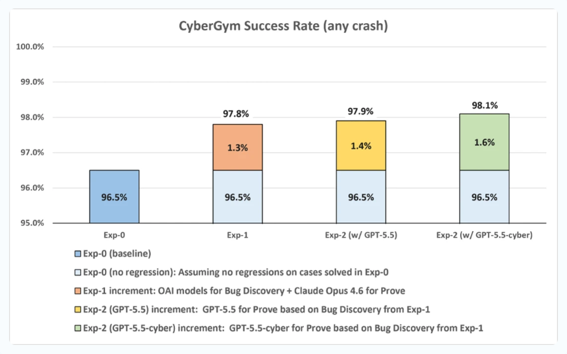
実験 1: バグ検出には最新の OpenAI モデル、実証には Claude Opus 4.6 を使用
構成: 準備 / スキャン / 検証: GPT-5.4、GPT-5.5、GPT-5.4-mini、GPT-5.3-codex。実証: Claude Opus 4.6。
結果: 52 件中 19 件が解決 (36.5%、任意のクラッシュ)。Exp-0 で既に解決済みのケースにリグレッションがないと仮定した場合、予測成功率: 97.8% (任意のクラッシュ)。
主な改善は、スキャン段階での検出結果の品質向上です。このデータセットにおける Exp-0 のベースラインと比較して、出力は仮説的なものが減って、より精度が高くなっており、具体的な実行詳細が含まれることで、検証精度と下流の実証生成の両方が向上しています。
CyberGym のベンチマークケース「arvo:3569」において、ベースラインは「いずれかのデストラクタやクリーンアップ コードが解放を試みた場合のリスク…」という曖昧な説明を生成する一方、GPT-5.5 は「210 行目で pj_default_destructor (P,…) を呼び出し、それが P->params および Q (= P->opaque) が解放される」という具体的な実行パスを特定しています。この根拠のある説明により、到達可能性について推論するための明確な道筋を得ることができます。
GPT-5.5 でもまた、検出されたバグとそれに対応する共通脆弱性分類 (CWE) カテゴリとの整合性が向上を示しており、より効果的な実証生成に寄与しています。
実験 2: 実験 1 で発見されたバグを用いて、実証に GPT-5.5 / GPT-5.5-cyber を使用
構成: 準備 / スキャン / 検証: 実験 1 におけるバグ検出の出力。Prove: GPT-5.5 / GPT-5.5-cyber。
結果 (GPT-5.5): 52 件中 21 件が解決 (40.4%、任意のクラッシュ)。Exp-0 で以前に解決されたケースにリグレッションがないと仮定した場合、予測成功率: 97.9% (任意のクラッシュ)。
結果 (GPT-5.5-cyber): 52 件中 23 件を解決 (44.2%、任意のクラッシュ)。Exp-0 で以前に解決されたケースにリグレッションがないと仮定した場合、予測成功率: 98.1% (任意のクラッシュ)。
実証段階において、GPT-5.5 と GPT-5.5-cyber の両モデルは、Claude Opus 4.6 よりも多くのクラッシュを検出しました。この向上は有意義ではあるものの、スキャン段階で観察された改善と比べると、控えめなものとなっております。このデータセットだけでは、これらのモデルがすべての概念実証生成タスクにおいて一貫して優れていると結論付けるには十分ではありません。
実証段階において、すべてのモデルに共通して 3 つの異なる戦略が見られました:
コード ベース、コードパスを推論して入力を生成する。
ファジング ベース、入力スペースを探索してクラッシュを探す。
カスタム インスツルメンテーション ベース、脆弱性に関連する変数を抽出し、それらをフィードバック シグナルとして活用し、入力の生成を導く。
3 つのモデルすべてが、52 件のケースにおいてこれら 3 つの戦略をすべて適用しましたが、どのターゲットに適用するかという点で異なり、その選択が結果の違いをもたらしました。arvo:61902 では、GPT-5.5-cyber のみが動作する概念実証を生成しました。これは、タスクをヒル クライミング問題として再定義するカスタム インストルメンテーションに基づくアプローチを適用したもので、「コーデックを十分に理解して、敵対的な音声を作成する」という課題を、「この値が 128 を超えるまで探索する」という課題に置き換えたものです。
スコアにとらわれない
CyberGym は、迅速な反復、継続的な評価、そして測定可能な進捗のための、極めて価値の高いプラットフォームとなっています。このフィードバックループを通じて、システムは飛躍的に進化し、ベンチマークでは 96.5% の性能を達成しました。さらに、新しいモデルはすでにそのベースラインをさらに 1%-2% 上回る改善をもたらしています。これほど短期間でこのレベルの性能を達成できたことは、この取り組みを支える基盤となるアーキテクチャ、研究の方向性、そしてエンジニアリングの厳密さを強く示しています。
同時に、私たちはこれらの結果を適切に解釈するよう細心の注意を払っています。96.5% という CyberGym スコアは、本システムが、既知の脆弱性からなる広範かつ困難なセットに対して効果的に推論できることを示しています。同様に重要なのは、これが評価フレームワークを拡張するオポチュニティがあることを示している点です。現実世界における脆弱性の発見には、曖昧さ、不完全な情報、そして絶えず進化するソフトウェア エコシステムといった要素が伴いますが、これらはいかなる固定されたベンチマークの枠をも超える次元です。まさにこれこそが、次のフェーズの取り組みを非常にエキサイティングなものにしている理由です。つまり、これらの能力をより現実的な環境へと適用し、ベンチマークでの卓越性から、現実世界へのインパクトへと、その最前線を押し広げていくことです。
今後の展望
私たちは、2 つの方向性で今後の方向性を定めていきます。
第一に、システムを真の実世界環境で稼働するよう進化させており、これまで未知だった脆弱性をコスト効率良く発見するとともに、大規模に問題をトリアージして修正するための統合機能と組み合わせています。バグを見つけることは、作業の半分に過ぎません。それをクローズすることが残りの半分です。
第二に、現実世界における脆弱性の発見が実際にどのように行われるか、その複雑さ、曖昧さ、そしてエンドツーエンドのワークフローを捉えるために、ベンチマークをさらに進化させる明確なオポチュニティがあると考えています。
モデルのバリエーション実験は、同じ結論を示しています。すなわち、システムとモデルは相互に補完し合うかたちで改善するということです。パイプラインによる性能向上が、単なるモデル向上によるものではないことを示すため、コア評価ではモデル構成を一定に保ち、新しいモデルについては別途テストを行いました。特にスキャン段階での検出精度において、さらなる向上が確認されました。それは、結果の解釈を複雑にするものではなく、ロードマップなのです。
AI スピードに対応した防御
再び 2 つの時計の話に戻りましょう。この取り組みの軌跡は、まさにそれらが入れ替わった瞬間の物語です。つまり、追いつくために必死に走る防御側から、AI を活用した分析によって、手動のプログラムでは到底維持できないほど広範な範囲をカバーし、プロセスのより早い段階で、本番コードのより深い部分まで到達できる防御側へと転じたのです。
これこそが、「AI スピード」が意味するものです。単にスキャン速度を高速化させるのではなく、今日におけるソフトウェアの実際の構築やリリースの在り方に歩調を合わせ続ける姿勢であり、パイプラインへのあらゆる改善が次の発見をより正確にし、システムとモデルが共に強化されていくことなのです。
詳細はこちら
コードネーム「MDASH」は、まだ始まったばかりです。私たちは次の章でも皆様とともに歩んでいきたいと考えています。
「コードネーム MDASH」をフォローし、プライベートプレビューに参加するには、サインアップしてください。「コードネーム MDASH」を支えるエンジニアリングの詳細については、弊社のテクニカル ブログ シリーズをご覧ください。

Microsoft Security ソリューションの詳細については、弊社のウェブサイトをご覧ください。セキュリティに関する専門家の解説を随時チェックできるよう、Security Blog をブックマークしてください。また、サイバーセキュリティに関する最新のニュースやアップデートについては、LinkedIn (Microsoft Security) および X (@MSFTSecurity) をフォローしてください。