
2026年06月08日 11時01分
AI

AIを実行するには大容量のメモリが必要であり、AIモデル側のメモリ使用量を削減する技術として「量子化」が広く用いられています。新たに、Googleが「学習段階で量子化をシミュレートする」というアプローチを採用した省メモリ版Gemma 4である「Gemma 4 QAT」を公開しました。
Gemma 4 with quantization-aware training
https://blog.google/innovation-and-ai/technology/developers-tools/quantization-aware-training-gemma-4/
一般的なPCでAIモデルをローカル実行する場合、まず超高速なVRAMにモデルが読み込まれます。VRAMに入りきらなかった分は比較的低速なRAMに読み込まれ、RAMにも収まらない場合はSSD上のスワップファイルに読み込まれることになります。このため、AIシステムを高速実行するにはVRAMに入りきるサイズのAIモデルを選択する必要があります。高性能なAIモデルはメモリ使用量が数十GB~数百GBになることが多いですが、AIモデルの計算精度を落としてメモリ使用量を削減する「量子化」と呼ばれる技術を用いることで、高性能AIモデルを家庭用PCで実行することができます。
公開されている量子化済みモデルの多くは完成済みのAIモデルに後から量子化を施したものであり、量子化が「計算精度を落とす」という仕組みである以上、どうしても応答品質が低下してしまいます。Gemma 4 QATはAIモデルの学習段階で量子化をシミュレートする「Quantization-Aware Training (QAT)」という技術を採用したモデルで、量子化による省メモリ化を実現しつつ、品質低下を抑えることに成功しています。
Gemma 4 QATはGemma 4の「E2B」「E4B」「12B」「26B A4B」「31B」のすべてのバリエーションに対応。また、E2BとE4Bはモバイル用途に最適化されたバージョンも用意されています。
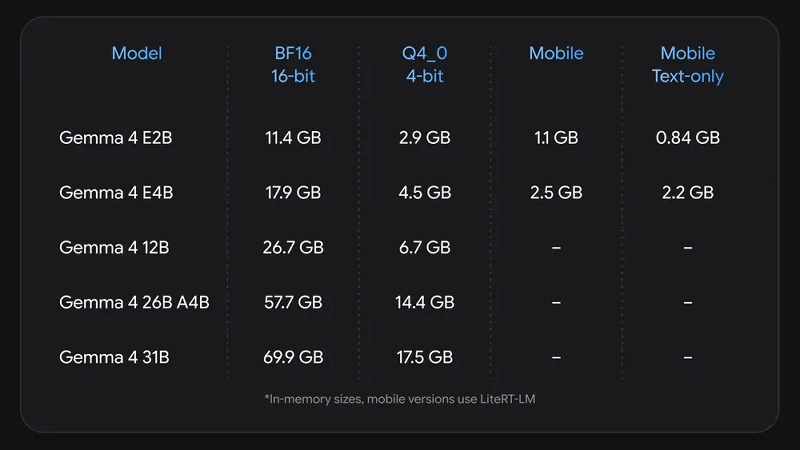
各モデルのメモリ使用量をまとめた図が以下。オリジナルのGemma 4 E2Bは11.4GBのメモリを消費しますが、QAT版(Q4_0 4-bit)は2.9GB、モバイル版は1.1GBに抑えられています。また、Gemma 4 E2Bの画像・音声認識能力を省いたテキスト限定モデルなら0.84GBという少ないメモリで実行可能です。そのほかのモデルについても品質低下を抑えつつ大幅なメモリ使用量削減に成功しています。
Gemma 4 QATの各モデルは以下のリンク先で配布されています。無料でダウンロード可能で、ライセンスはApache License 2.0です。また、llama.cppやOllama、LM Studioで実行可能なことも明言されています。
Gemma 4 QAT Q4_0 – a google Collection
https://huggingface.co/collections/google/gemma-4-qat-q4-0
この記事のタイトルとURLをコピーする
・関連記事
GoogleがオープンAIモデル「Gemma 4」を発表、ライセンスをApache 2.0に変更 – GIGAZINE
GoogleがノートPCで実行可能なAIモデル「Gemma 4 12B」を無料公開、16GBのVRAMがあれば実行可能 – GIGAZINE
無料でGoogleのローカルAI「Gemma 4」の威力がGoogle公式アプリ「AI Edge Gallery」で誰でも試せるように、iPhoneでもローカル動作可能 – GIGAZINE
小型AIで下書きを生成して大型AIを爆速化する「マルチトークン予測」という技術をGoogleが発表 – GIGAZINE
ノートPCで動くGoogle製「Gemma 4 12B」がエンコーダー不要で画像&音声を処理する仕組みとは? – GIGAZINE