本ブログは 2026 年 4 月 8 日に公開された Amazon Science Blog “How Amazon uses agentic AI for vulnerability detection at global scale” を翻訳したものです。
Amazon の RuleForge システムは、エージェンティック AI を活用して、従来の手法より 336% 速く本番環境向けの検出ルールを生成します。
2025 年、NVD (米国国立脆弱性データベース) には 48,000 件を超える新しい CVE (共通脆弱性識別子) が公開されました。これは、自動化ツールや AI を活用したツールが脆弱性発見に与える影響を反映しています。しかし、セキュリティチームにとっては、新しい脆弱性を把握するだけでは十分ではありません。各開示情報を、大規模で複雑なシステムを保護するのに十分な速度で、堅牢な検出ロジックに変換する必要があります。
そこで AWS が構築したのが RuleForge です。RuleForge は、脆弱性を悪用するコードのサンプルから直接検出ルールを生成するエージェンティック AI システムです。本番セキュリティシステムに求められる精度を維持しつつ、お客様のセキュリティを強化しながら、手動でのルール作成と比較して 336% 速く検出ルールを生成しています。
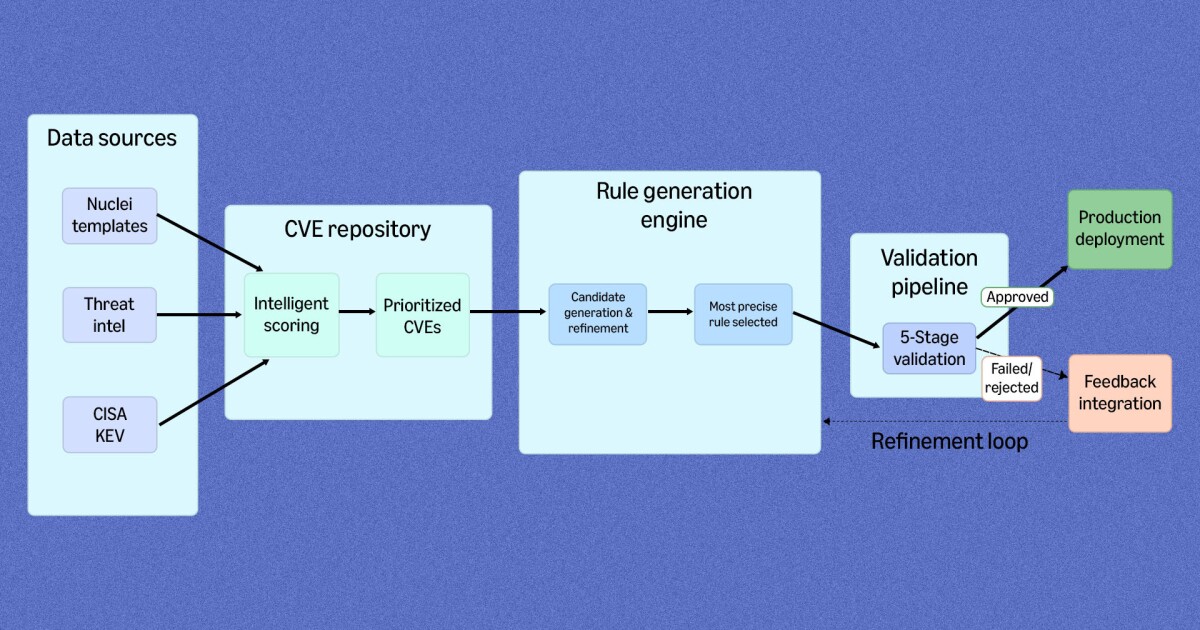
CVE リポジトリ、ルール生成、検証、フィードバック統合のコンポーネントを示す RuleForge のアーキテクチャ。
開示から防御までのギャップの解消
Amazon では、検出ルールは JSON で記述され、MadPot へのリクエストなどのデータに適用されます。MadPot は、デジタルおとりを使って悪意のあるハッカーの動作を捕捉する世界規模の「ハニーポット」システムです。また、社内の検出システムである Sonaris が検知した、エクスプロイトの試行と思われるものにも適用されます。NVD で公開される高深刻度の脆弱性の数は今後も増加し続けると予想されるため、大規模なセキュリティ運用には AI を活用した自動化が不可欠です。
ルール生成を自動化することで、私たちはそのギャップを埋めながら、対応範囲を拡大しています。チームは現在、従来の手法では不可能だったペースと規模で、高深刻度の CVE を検証済みの検出ルールに変換できるようになり、お客様により包括的な保護を提供しています。
手動の検出ルールワークフロー
RuleForge 登場以前、新しい CVE に対する検出ルールの作成は、アナリスト主導の複数ステップから成るプロセスでした。
ダウンロードと分析: セキュリティアナリストは、公開されている概念実証 (PoC) エクスプロイトコード (脆弱性を悪用する方法を示すコード) を見つけ出し、それを調査して攻撃メカニズム、入力、想定される動作を把握
検出ロジックの作成: アナリストは脆弱性を狙う悪意のあるトラフィックを捕捉するルールを作成し、トラフィックログに対するルールの精度を測定するクエリを記述
検証とイテレーション: アナリストはこれらのクエリを実行し、結果を確認し、誤検知 (False Positive) を減らすためにルールを調整するという作業を、ルールが本番環境で十分に機能するまで繰り返し
ピアレビューとデプロイ: 最後にアナリストは、デプロイ前に別のセキュリティエンジニアによるコードレビューを受けるためにルールを提出
このワークフローは高品質なルールを生み出す一方で、時間がかかるため、チームはどの脆弱性を最初にカバーするかを慎重に優先順位付けする必要がありました。
エージェンティック AI パイプラインとしてのルール作成の再構築
RuleForge は、このワークフローをエージェンティック AI システムとして再構想したものです。検出ルールの生成、評価、改良を協調して行う特化型 AI エージェント群で構成されており、最終承認には引き続き人間が関与します。単一のモデルでエンドツーエンドに問題を解決しようとするのではなく、RuleForge はタスクを人間の専門家の働き方を模した段階に分解します。
自動取り込みと優先順位付け: RuleForge は、特定の脆弱性を狙う方法を示す公開済みの PoC エクスプロイトコードをダウンロードします。コンテンツ分析と脅威インテリジェンスソースを使用して各エクスプロイトをスコアリングします。これにより、ルール生成が最も重要な脅威に集中することが保証されます
並列ルール生成: 優先順位付けされた各 CVE について、AWS Fargate 上で Amazon Bedrock を使用して動作するルール生成エージェント (generation agent) が、複数の検出ルール候補を並列に提案します。各候補は、後段のステージからのフィードバックに基づいて複数のイテレーションで改良できるため、システムは最も有望なものを選択する前に、さまざまな検出戦略を検討できます。一人の専門家がルールを 1 つずつ作成するのに頼るのではなく、RuleForge は検出エンジニアリングを、AI が選択肢を提案し人間がデプロイの可否を決定するパイプラインとして扱います
AI を活用した評価: 個別のルール評価エージェント (evaluation agent) が各候補をレビューします。これは RuleForge の重要な革新の 1 つです。生成モデル (generation model) が自身の作品を判断するのではなく、RuleForge は専用の「ジャッジ」モデル (judge model) を使用して、人間の専門家が検出ルールを評価する際に用いる 2 つの次元で各ルールをスコアリングします。
感度 (sensitivity): このルールが CVE で説明されている悪意のあるリクエストを検知できない確率はどのくらいか?
特異度 (specificity): このルールが脆弱性そのものではなく、脆弱性と相関する特徴を狙っている確率はどのくらいか?
多段階検証: ジャッジを通過したルールは、段階的に厳格になるテストパイプラインを通過します。合成テストでは、悪意のあるテストケースと無害なテストケースの両方を生成し、基本的な検出精度を検証します。次に、ルールは MadPot などのトラフィックログに対して検証され、期待どおりに動作することを確認します。いずれかの段階で失敗したルールは、理由を説明する具体的なフィードバックとともにルール生成エージェントに送り返され、改善のクローズドループを形成します
人間によるレビューとデプロイ: 最高のパフォーマンスを発揮するルールは、以前と同様にコードレビューに進みます。セキュリティエンジニアがレビューを行い、フィードバックは修正のためにルール生成エージェントに戻されます。本番デプロイ前の最終ゲートには、引き続き人間の判断が残ります
RuleForge の 5 × 5 生成戦略を表した図。5 つの並列検出ルール候補、それらの信頼度スコア、および反復的な改良を示しています。システムは複数の候補を同時に生成し、検証結果に基づいて最高のパフォーマンスを発揮するものを選択します。
個別のジャッジモデルが重要な理由
ルール生成モデルに対して自身の検出ルール候補への信頼度を報告するよう求めたところ、生成したほぼすべてのものを良いと判断しました。これは、セキュリティトピックにおける LLM のキャリブレーションが不十分であることを示す研究結果と一致しています。
その解決策は、生成と評価を分離することでした。専用のジャッジモデルを使用することで、真陽性 (True Positive) の検出数を維持しながら、誤検知を 67% 削減できました。
ジャッジを効果的にしたのは、主に 2 つの設計選択です。
否定的な表現が精度を向上させる:「ルールが悪意のあるリクエストを検知できない確率はどのくらいか?」と尋ねた方が、「ルールがすべての悪意のあるリクエストを正しく検知する確率はどのくらいか?」と尋ねるよりも、より良いキャリブレーションが得られます。LLM は肯定に傾く傾向があるため、評価を問題探しとして組み立てることで、より誠実な評価が得られます
ドメイン固有のプロンプトは汎用的なものより優れている: 単にモデルにルールへの全体的な信頼度を評価するように依頼するだけでは、キャリブレーションが不十分になりました。うまくいった質問は、セキュリティエンジニアが実際に注目する観点を組み込んだものでした。たとえば、ルールが相関する表面的な特徴ではなく脆弱性メカニズム自体を狙っているか、ルールがエクスプロイトのバリエーションの全範囲をカバーしているかといった観点です
システムは、スコアを説明する推論チェーンも生成します。私たちはこれらの推論チェーンを人間の評価と照らし合わせて評価し、9 つのルールのうち 6 つで AI ジャッジの推論が人間の専門家の推論と一致することを確認しました。たとえば、人間の評価者が「あの SQL インジェクションの正規表現はゆるすぎる」と指摘した際、ジャッジは独立して「正規表現パターンはシングルクォートを含むあらゆるクエリパラメータを捕捉するため、特定の脆弱性だけよりも範囲が広い」と判断していました。
結果と今後の展望
私たちは 2025 年 8 月に信頼度スコアリングシステムをデプロイし、アナリストが新しい検出ルールをデプロイする速度を加速させました。その年の最後の 4 か月間で、RuleForge により、本番セキュリティシステムに必要な高い精度を維持しながら、手動より 336% 速くルールを生成および検証できるようになりました。アナリストの焦点を作成からレビューに移すことで、品質を損なうことなく全体的なスループットを大幅に向上させました。脆弱性開示と防御の間のギャップをこれまで以上に効果的に埋めることで、AWS 上のお客様のワークロードを守るマネージド保護がより速く更新され、より多くの高深刻度の CVE をカバーできるようになっています。
RuleForge は、エージェンティック AI が精度要件を満たしながら、本番規模で人間のセキュリティ専門知識を強化できることを実証しています。重要な革新はアーキテクチャ的なものです。ルール生成とルール評価の分離、単一のモデルではなく複数の特化型 AI エージェントの使用、そして最終承認のためのヒューマンインザループの維持です。脆弱性開示の頻度が加速し続ける中、これらの設計原則は、防御を最新の状態に保つのに役立ちます。
評価方法論や実験結果を含む RuleForge の技術的詳細について詳しくは、私たちが arXiv で公開している論文を参照してください。
著者について
C. J. Moses は Amazon の chief information security officer 兼 vice president of security engineering です。
本ブログは Security Solutions Architect の 中島 章博 が翻訳しました。