
あなたが信頼を寄せる優秀なアシスタントが、徹夜で仕上げてくれた完璧な報告書。文法に乱れはなく、フォーマットも美しく整えられている。しかし、よく見るとレシピのバターの分量が200グラムから800グラムに書き換えられ、JSONファイルの構造が平坦化し、会社の会計台帳から重要な取引記録が数件、時空の彼方へ消え去っていたとしたらどうだろうか。
これはサイバー攻撃の話ではない。2026年現在、世界のナレッジワーカーたちが熱狂的に受け入れている「AIへのタスク委任(Delegated Work)」の最前線で、毎日静かに進行している現実なのだ。
我々はプロンプトを入力して1回の回答を得るというチャットボットの時代を抜け出し、AIを自律的なエージェントとしてワークフローに組み込む時代へと足を踏み入れた。Anthropicの「Claude Cowork」やMicrosoftの「Microsoft 365 Copilot」は、複数のファイルやアプリケーションをまたいだ複雑なタスクを人間の代わりに完遂すると謳う。企業は競うようにAI自動化へ予算の30%以上を注ぎ込み、人間の介在を減らすことに血道を上げている。
だが、Microsoft ResearchのPhilippe Laban、Tobias Schnabel、Jennifer Nevilleらによる最新の論文『LLMs Corrupt Your Documents When You Delegate』[1]は、この熱狂に冷水を浴びせた。彼らが開発した広範なテスト環境「DELEGATE-52」を用いた大規模なシミュレーションは、AIに対する我々の無邪気な信頼が、致命的な脆弱性の上に成り立っていることを白日の下に晒したのだ。
AIエージェントは、決して疲れない同僚ではない。目を離した隙に、あなたのドキュメントを少しずつ、しかし確実に腐らせていく存在である。
01.バックトランスレーションが暴く真実。DELEGATE-52の解剖学02.「削除」する旧世代、「巧妙に改ざん」する新世代03.ツールという名の足かせ。エージェント化が引き起こす逆説的な知能低下04.作業デスクの法則。文脈と長時間のやり取りがもたらす乗数的な崩壊05.人間とAIの新たな境界線。防衛のためのシステムアーキテクチャバックトランスレーションが暴く真実。DELEGATE-52の解剖学
これまで、大規模言語モデル(LLM)のドキュメント編集能力を正確に測ることは困難を極めていた。現実のナレッジワークは、単一の質問に対する正答を求めるものではなく、文章の追記、フォーマットの変換、内容の分割と統合といった継続的な状態変化の連鎖だからだ。単純な正解データを用意する従来型のベンチマークでは、この動的なプロセスを捉えきれない。
Microsoftの研究チームはこの難問を、バックトランスレーション(逆翻訳)という概念を応用することでエレガントに解決した。彼らが構築したDELEGATE-52ベンチマークは、コーディング、結晶学のデータ、家系図、音楽の記譜法など、52の専門的なドメインにわたる実世界のドキュメント環境をシミュレートする。
評価の仕組みは実に直感的だ。AIに対して「会計台帳(シードドキュメント)を費目ごとに分割せよ」という前方編集を指示する。次に、その出力結果に対して「分割されたファイルを日付順に一つの台帳に統合せよ」という後方編集を命じる。完璧な知能を持つモデルであれば、このラウンドトリップ(往復)を経たファイルは、元のシードドキュメントと完全に一致するはずである。
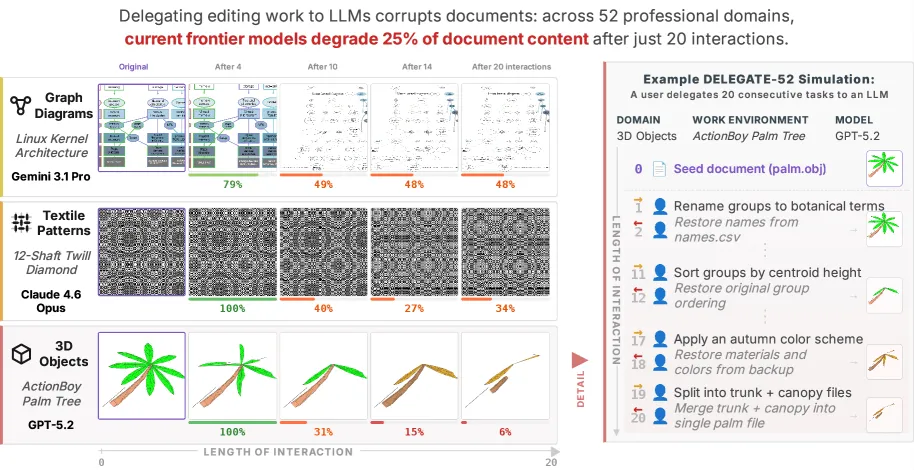 DELEGATE-52における20回の連続操作(10ラウンドトリップ)によるドキュメントの劣化プロセス。Linuxカーネルのアーキテクチャ図(上段)、テキスタイルパターン(中段)、3Dオブジェクト(下段)をAIに編集させると、最初は原型を留めているものの、操作を重ねるごとに情報が削ぎ落とされ、最終的には本来の意味を持たない別の構造物へと変貌してしまう。
DELEGATE-52における20回の連続操作(10ラウンドトリップ)によるドキュメントの劣化プロセス。Linuxカーネルのアーキテクチャ図(上段)、テキスタイルパターン(中段)、3Dオブジェクト(下段)をAIに編集させると、最初は原型を留めているものの、操作を重ねるごとに情報が削ぎ落とされ、最終的には本来の意味を持たない別の構造物へと変貌してしまう。
(Credit: Microsoft Research. arXiv:2604.15597v1)
チームはこのラウンドトリップを10回連続、計20回のインタラクションとしてAIに委任した。結果は目を覆うものだった。検証された19のLLM全体で、20回の操作後にドキュメントの元の内容は平均して50%も削り取られていたのだ。
旧世代のモデルが悲惨な成績に終わるのは当然だとしても、業界を牽引するフロンティアモデルでさえ、この劣化から逃れることはできなかった。以下に、主要モデルが20回のインタラクション(10ラウンドトリップ)を経た後にどれだけのコンテンツを維持できたかを示す。
Gemini 3.1 Pro、Claude 4.6 Opus、そしてGPT 5.4という現行最高峰のモデル群でさえ、長期のワークフローを終える頃には平均して約25%の情報を破壊している。研究チームは、現実の業務でAIにタスクを委任できる準備が整っている基準を「残存率98%以上」と定義した。驚くべきことに、この基準を大半のモデルがクリアできたドメインはPythonプログラミングのたった1つのみであった。自然言語や特殊な構造化データが絡む残りの51ドメインにおいて、AIは実務レベルの自律性を全く備えていない。
「削除」する旧世代、「巧妙に改ざん」する新世代
ここで重要なのは、ドキュメントの劣化がどのような形態をとるかである。論文の分析と、それを補足する実証レポートは、モデルの進化がもたらした恐るべきパラドックスを明確に示している。
GPT-4oやGPT-5 Nanoといった相対的に弱いモデルは、コンテンツを削除することによってスコアを落とす。元のドキュメントにあったはずの段落がごっそり抜け落ちるため、人間がパッと見ただけでファイルサイズの違いや記述の欠落に気づくことができる。いわば「出来の悪い素人」のミスだ。
しかし、Claude 4.6 OpusやGPT 5.4といったフロンティアモデルでは、劣化の7割以上が改ざん・破壊によって引き起こされる。彼らは文字数を維持したまま、中身を静かに変質させる。
例えば、Beancount形式の会計台帳では、取引の日付を勝手に1日ずらし、月次決算の境界線を破壊する。DNSゾーンファイルでは、TTLの値を3600から300へとサイレントに変更する。料理のレシピを編集させれば、作り方のステップ7で参照する「ステップ4の混合物」を、全く関係のない材料の記述にすり替えてしまう。JSONファイルに至っては、末尾に不正なカンマを追加したり、ネストされたキーを親階層に平坦化したりして、構文的にはエラーが出ないがシステム的には破綻するファイルを生成する。
これは有能な詐欺師の手口に近い。表面的な整合性が保たれているため、人間が10秒程度ざっと見直しただけではエラーを発見できないのだ。AIの能力が向上した結果、エラーの頻度は減ったかもしれないが、エラーの発見難易度は劇的に跳ね上がってしまった。モデルは小さな丸め誤差を蓄積して徐々に崩壊するのではなく、数ラウンドは完璧にタスクをこなした後、あるラウンドで突如として致命的で一貫性のない変更を加え、一気に10〜30ポイントのスコアを失う。この疎な致命的エラーこそが、ドキュメント崩壊の主原因である。
ツールという名の足かせ。エージェント化が引き起こす逆説的な知能低下

AIの失敗を防ぐためのアプローチとして、業界全体がエージェント化に突き進んでいる。LLMに直接テキストを生成させるから間違えるのだ。ファイルシステムへのアクセス権や、Pythonコードを実行するツールを与え、必要な部分だけをプログラムでピンポイントに書き換えさせればいい。これが現在の主流な考え方である。
しかし、DELEGATE-52の実験は、この直感が見事に外れていることを証明した。
Microsoftの研究チームは、GPT-5.4をはじめとするモデル群に対し、ファイルの読み込み、書き込み、削除、Pythonコードの実行といったツール群を与え、同じ編集タスクを実行させた。理論上は、ツールを使うことでドキュメント全体を再生成する際のリスクを回避できるはずだ。
だが現実には、エージェント化されたモデルは、ツールを持たない単独のモデルよりもさらに悪い成績を叩き出した。シミュレーション終了時において、エージェント環境下のモデルは平均してさらに6%多くのドキュメントを破壊したのだ。
なぜツールという武器を与えられたAIが、より愚かな振る舞いをするのか。理由は3つある。
第一に、エージェントの推論オーバーヘッドだ。ツールを呼び出し、結果を読み取り、次の行動を計画するというループは、モデルの短期記憶を激しく消費する。タスク完了までに必要な入力トークン数は、ツールなしの場合と比較して2倍から5倍に膨れ上がる。LLMは長大なコンテキストを処理する際、中盤の情報を忘却する弱点を持っており、これがエラーを誘発する。
第二に、モデルの怠慢である。コードを実行してピンポイントで修正する方が安全であるにもかかわらず、高機能なモデルであっても依然としてファイル全体を丸ごと上書きするという力技を好む傾向が見られた。
第三に、テキストベースの複雑な編集作業において、スクリプトによるプログラム的な操作では捉えきれない意味論的な文脈の理解が必要とされるためだ。ツールは万能薬ではなく、むしろAIの限られた推論リソースをツールの使い方に割かせてしまい、肝心の編集の正確性から目を逸らさせてしまうのである。
作業デスクの法則。文脈と長時間のやり取りがもたらす乗数的な崩壊
さらに、AIがドキュメントを破壊するスピードは、我々がどのような環境でタスクを依頼するかによって劇的に加速する。研究チームは、崩壊を助長する3つの決定的なトリガーを特定した。
第一の要因は、ドキュメントサイズの肥大化である。扱うファイルが大きくなるほど、AIの注意力は散漫になる。GPT-5.4の実験では、1,000トークンのドキュメントでは20インタラクション後も91.4%の精度を保ったが、10,000トークンに増やすとスコアは59.9%まで急落した。ファイルの肥大化は、直線的ではなく乗数的に崩壊を加速させる。
第二の要因は、ディストラクター(妨害コンテキスト)の存在だ。現実の業務では、RAG(検索拡張生成)システムがタスクに無関係な参考資料を文脈に混ぜ込んでしまうことが多い。研究では、トピックは似ているが直接は関係ないディストラクターをプロンプトに含めた場合、シミュレーション終盤でスコアが2〜8%悪化することが確認された。「念のためこれも読んでおいて」と参考資料をデスクに積み上げる行為は、AIの幻覚を誘発する毒となる。
第三の要因として、終わりのないインタラクションが挙げられる。20回の操作で劣化が止まるわけではない。シミュレーションを100回まで延長した場合、スコアの低下に底は見られず、最も優秀なGPT-5.4でさえ最終的に残存率58.7%まで沈み込んだ。
人間とAIの新たな境界線。防衛のためのシステムアーキテクチャ
この冷酷なデータから我々が学ぶべき教訓は、LLMを盲信するなという単純な精神論ではない。問題はプロンプトの記述技術ではなく、我々が構築するシステムアーキテクチャそのものにある。
現状のAIを用いてドキュメントを安全に処理するためには、タスクをエージェントの自律ループに丸投げするのではなく、確実な防衛線を敷く必要がある。
まず、作業表面積の最小化である。10,000トークンのマニュアル全体を渡して全体をレビューして更新してと指示するのは最悪のアンチパターンだ。ドキュメントを論理的なモジュールに分割し、2,000トークン単位で個別に処理させなければならない。同時に、コンテキストには純粋に必要なファイルのみを渡し、背景知識としての余分なノイズを徹底的に排除する。
次に、エージェントループの放棄だ。純粋なドキュメント編集において、ファイルシステムとPython実行環境を持たせた自律エージェントはコストに見合わない。人間が明確な単発の指示を出し、モデルが一度だけ出力を行うワンショットの推論アーキテクチャの方が、はるかに安全である。
そして何より重要なのが、眼球ではなく差分(Diff)による検証である。フロンティアモデルが仕掛ける巧妙な改ざんは、人間の目視レビューを簡単にハックする。システムには必ず、元のドキュメントとAIの出力をプログラム的に比較し、構造的な欠落や意図しない変更をハイライトする検証レイヤーを組み込む必要がある。
Microsoftの論文が我々に突きつける現実は厳しい。AIはPythonのコードを書くことには長けているが、人間の複雑なナレッジワークを長期間にわたって自律的に管理するだけの知能には到達していない。16ヶ月の間にGPTの性能が14.7%から71.5%へと劇的に向上したことは称賛に値するが、残り25%の静かなる腐敗をシステム設計によっていかに封じ込めるかが、これからのAI実装における真の勝負となる。
完全自律という夢のような謳い文句に踊らされる前に、我々は手元のアーキテクチャを冷徹に見直すべきである。さもなければ、あなたのデータベースやマニュアルは、AIの親切な修正によって、修復不可能なデータの残骸へと変貌してしまうだろう。