2026年4月、OpenAIは驚異的な機能を備えた2つの大きなアップデートを発表した。一つは、単なる画像生成の枠を超え、現実のデータに基づいたテキストや文脈を画像内に取り込める「ChatGPT Images 2.0」である。もう一つは、従来の「GPT-5.4」から処理速度と精度を向上させた最新のフロンティアモデル「GPT-5.5」だ。
筆者は、このリリース直後からChatGPT Images 2.0のコンテキストの認識能力を検証してきた。その結果は非常に優れたものだったが、一方で、気になるのは基本的な画像生成能力だ。果たして性能は向上したのか、それとも現状維持、あるいは劣化しているのだろうか。
この疑問を解明するため、筆者はGoogleの「Gemini」で提供されている「Nano Banana」との比較検証を実施した。2025年12月のテストでは、Nano Bananaが93%という高得点を叩き出したのに対し、ChatGPTはポップカルチャーに関する生成を拒否したこともあり、74%という芳しくない結果に終わっていた。今回は、両者の現在の実力を正確に測定するため、過去のデータとの比較ではなく、両モデルに対して同一のテストを改めて実行した。
なお、本稿における「Gemini」「Nano Banana」「Google」は、Google Geminiの画像生成機能であるNano Bananaを指す。また「Images 2.0」は、ChatGPTの画像生成モードを指している。
先に結論を言えば、今回のスコアはChatGPT Images 2.0が97%を記録し、Gemini Nano Bananaの85%を大きく上回った。しかし、テストの最終盤では、極めて不可解で不快な現象も確認された。その詳細を含めて検証結果をレポートする。
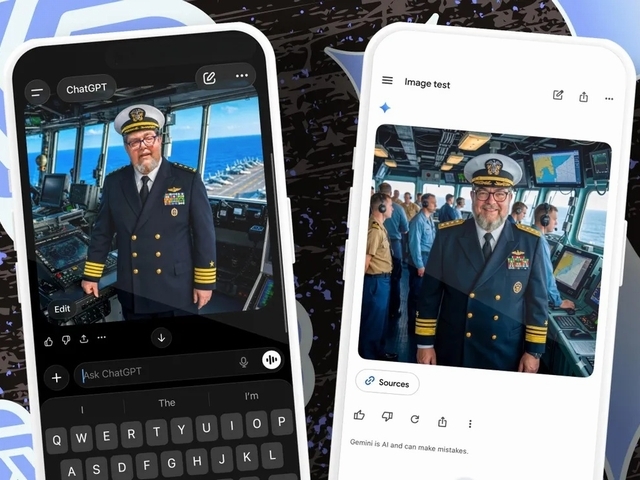
テスト1:海軍提督の肖像によるコンテキスト理解力
配点:15点、ChatGPT Images 2.0:14点、Gemini Nano Banana:12点

提供:David Gewirtz / ZDNET(ChatGPT ImagesおよびGemini Nano Bananaで作成)
プロンプト:
「この男性に米国海軍提督の制服を着せ、空母の艦橋に配置してください。顔は変更しないでください。縦横比は1:1です。」
最初のテストは、適切な背景と適切な服装をそれぞれ生成すること、そして、被写体の顔と体の維持という3つの重要な要素を評価する。
背景の構成については両者とも合格点だった。制服の生成も一見すると提督らしく見えるが、細部では階級章の混同や架空の装飾が見られたため、両者に1点ずつの減点を行った。
決定的な差が出たのは顔の再現性だ。ChatGPTが元の顔を完璧に維持したのに対し、Geminiは不自然な笑顔になり、筆者の実物よりも立派な髭を描き加えた。この再現性の欠如により、Nano Bananaはさらに2点を失った。
ZDNET Japan 記事を毎朝メールでまとめ読み(登録無料)