

ユーザーの感情や音響的ニュアンスを理解、より自然な応答が可能
7
会員(無料)になると、いいね!でマイページに保存できます。
共有する
米Googleは2026年3月26日、リアルタイム対話機能を強化した新音声モデル「Gemini 3.1 Flash Live」を発表した 。ユーザーの感情や音響的ニュアンスを理解し、より自然な応答が可能になった 。一般向けの「Gemini Live」や「Search Live」のほか、開発者や企業向けにも提供が開始され、日本を含む200以上の国と地域で利用できる。

(画像:Google)
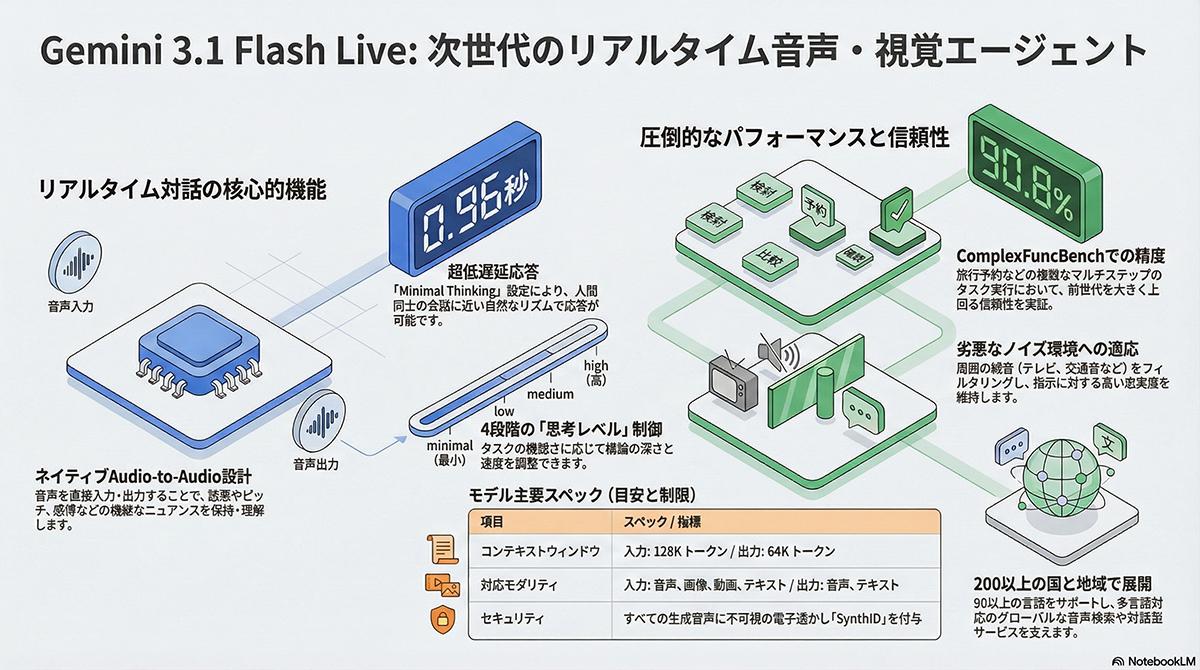
米Googleは2026年3月26日、自社のリアルタイム対話機能を強化する新たな音声モデル「Gemini 3.1 Flash Live」を発表した。同モデルは「Gemini 3 Pro」をベースとしたネイティブなマルチモーダル推論モデルであり、最大12万8000トークンのコンテキストウィンドウを備え、音声、画像、動画、テキストを処理して自然な出力を行う。
従来のモデルと比較して処理精度の向上と遅延の大幅な低減が図られており、以前の「2.5 Flash Native Audio」に比べて声の高さや話すペースといった音響的なニュアンスを理解する能力が向上した。これにより、ユーザーの不満や混乱などの感情表現に合わせて動的に応答を調整することが可能となっている。さらに、会話の文脈を従来の2倍長く維持できるようになり、長時間のブレインストーミングや、ノイズの多い環境下での複雑なタスク処理に役立つ設計となっている。
【図版付き記事はこちら】Googleが新音声モデル「Gemini 3.1 Flash Live」発表Googleが新音声モデル「Gemini 3.1 Flash Live」発表
(図版:ビジネス+IT)
外部の評価機関によるベンチマークテストにおいても高い性能を示しており、米Scale AIが実施した音声モデルの会話能力評価「Audio MultiChallenge」において、「thinking」機能をオンにした状態で36.1%というスコアを記録した。このテストは複雑な指示への対応や、現実世界の音声に特有の途切れやためらいを含む状況下での長期的な文脈維持能力を評価するものである。
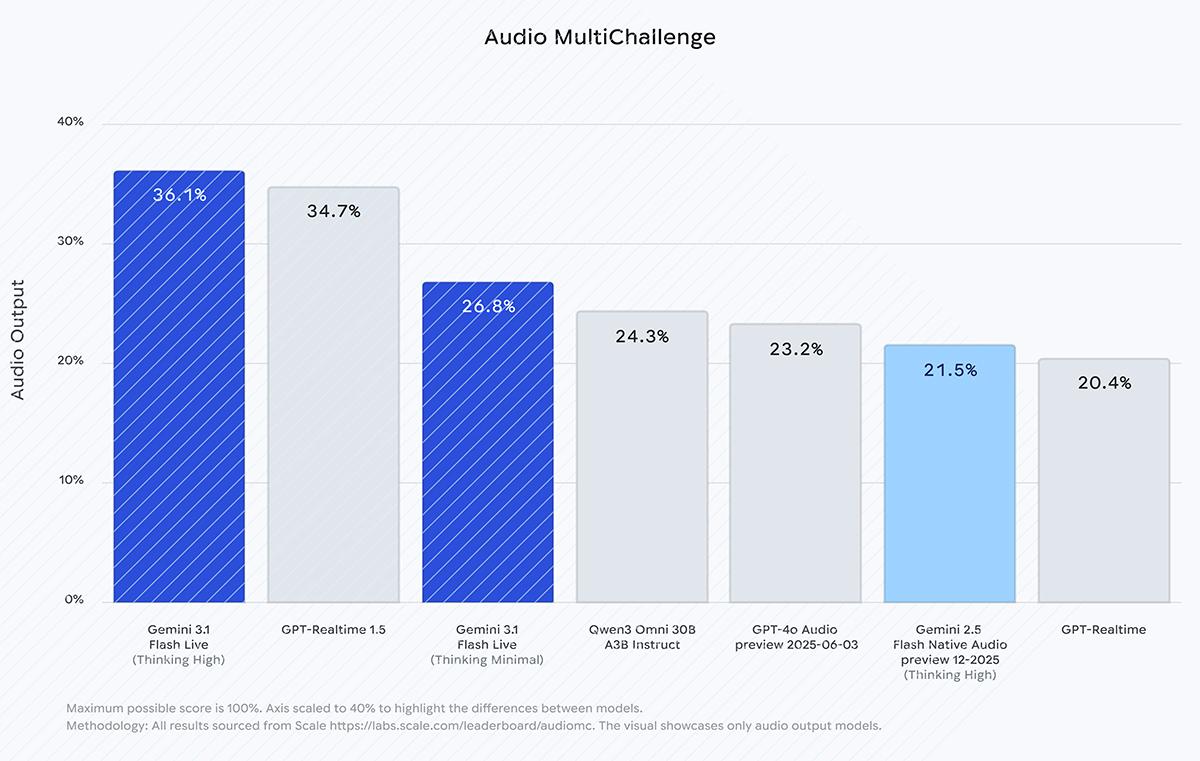
音声言語モデルの会話能力を評価するベンチ「オーディオマルチチャレンジ」で高いパフォーマンス
(図版:Google DeepMind)
また、複数の制約条件を伴う関数呼び出しを評価する「ComplexFuncBench Audio」でも90.8%のスコアを達成している。同モデルは、一般ユーザー向けに日本を含む200以上の国と地域に拡大された「Search Live」や「Gemini Live」を通じて利用可能となっている。開発者向けには「Google AI Studio」を通じて「Gemini Live API」のプレビュー版として提供され、企業向けには「Gemini Enterprise for Customer Experience」に組み込まれている。
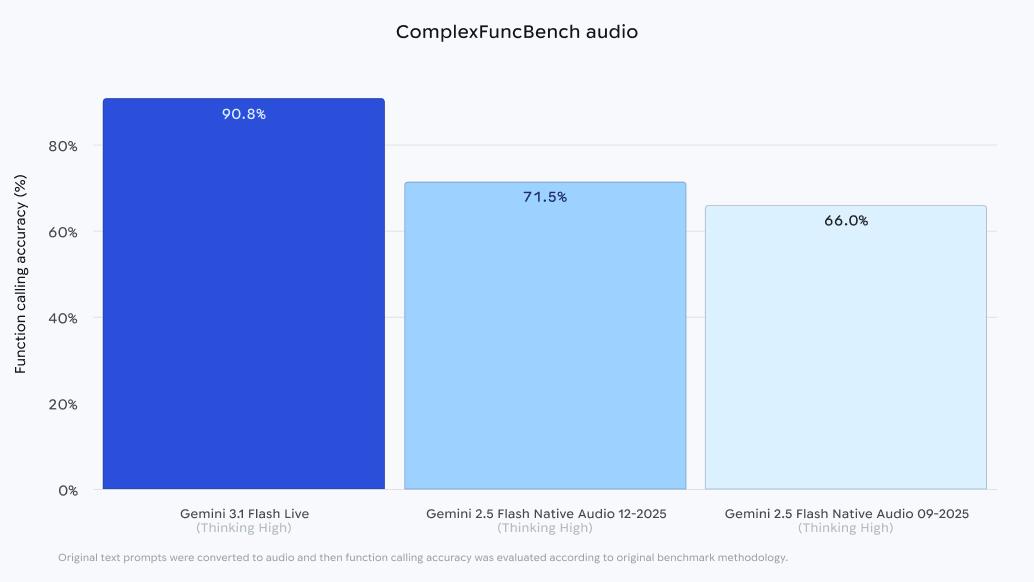
マルチステップのベンチマークであるComplexFuncBench Audioでも90.8%という高いスコアを獲得
(図版:Google DeepMind)
安全性に関する対策として、GoogleのAI原則と生成AIポリシーに準拠した開発が行われている。児童の搾取やヘイトスピーチ、危険なコンテンツの生成を防ぐため専門チームによる評価とレビューを実施した。また、AIによる誤情報の拡散を防止するため、同モデルで生成されたすべての音声には人間には感知できない電子透かし「SynthID」が直接埋め込まれており、AI生成コンテンツであることを高い信頼性で検出できる仕組みが整えられている。
評価する
いいね!でぜひ著者を応援してください
会員(無料)になると、いいね!でマイページに保存できます。
AI・生成AIのおすすめコンテンツ
関連タグ