

2026
4/10
当サイトは Google Adsense、Amazon アソシエイト等 アフィリエイト広告を利用して収益を得ています.
Google は 2026 年 4 月 7 日(現地時間)時点で、Android アプリ開発で使用する AI モデルの能力を測定するベンチマーク「Android Bench」(Android LLM Leaderboard)の最新結果を公開しました。
今回の更新によって OpenAI の GPT-5.4 および GPT-5.3-Codex が追加され、GPT-5.4 が Google の Gemini 3.1 Pro Preview と同率で首位となっています。
目次
Android アプリ開発に特化した評価指標
「Android Bench」は、2026 年 3 月に Google が公開した独自の評価指標で、既存のベンチマークでは測定しきれない Android 開発特有の課題に焦点を当てています。
これには、UI 構築の Jetpack Compose や、非同期処理の Coroutines と Flows、データ保存の Room、依存性注入の Hilt といった要素を AI がどの程度扱えるかが含まれています。
Google は、開発者の生産性を向上させ、Android エコシステム全体でより高品質なアプリを生み出すための指標として、このテスト結果を公開しています。
最新のランキングとスコア状況
2026 年 4 月 7 日時点の最新ランキングでは、新たに追加された GPT-5.4 が 72.4% のスコアを記録し、これまで単独首位だった Gemini 3.1 Pro Preview に並んでいます。また、同じく追加された GPT-5.3-Codex も 67.7% を獲得し、3 位にランクインしました。
今回のテスト結果における主な AI モデルのスコアは以下の通りです。
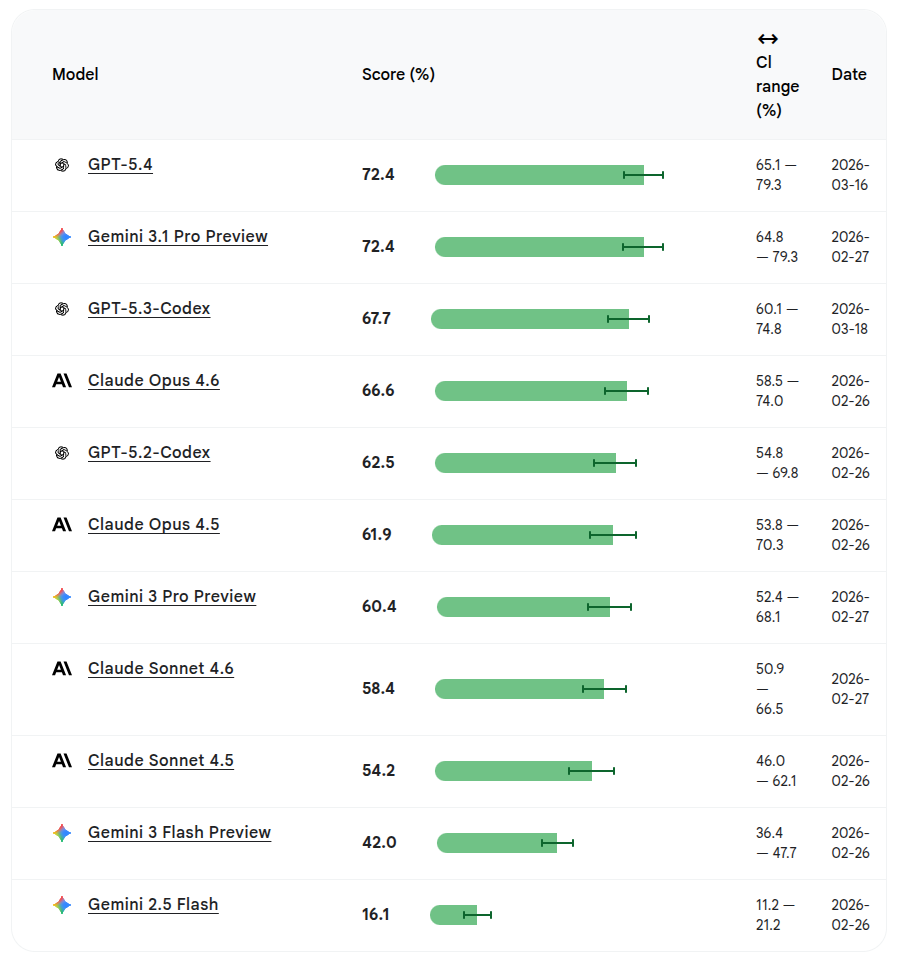
GPT-5.4 : 72.4% (新規)
Gemini 3.1 Pro Preview : 72.4%
GPT-5.3-Codex : 67.7% (新規)
Claude Opus 4.6 : 66.6%
GPT-5.2-Codex : 62.5%
Claude Opus 4.5 : 61.9%
Gemini 3 Pro Preview : 60.4%
Claude Sonnet 4.6 : 58.4%
Claude Sonnet 4.5 : 54.2%
Gemini 3 Flash Preview : 42.0%
Gemini 2.5 Flash : 16.1%
これより下位のモデルは、2 月下旬の初回テスト時のデータから変動はありません。
なお、スコアは 100 のテストケースを 10 回実行し、正常に解決できた平均割合を示しています。スコアには統計的な信頼性を示す信頼区間(CI)も設定されており、上位モデルは 60% 台から 70% 台後半のパフォーマンスを安定して発揮できることが確認されています。
まとめ
「Android Bench」の更新により、GPT-5.4 と Gemini 3.1 Pro Preview が現在の Android アプリ開発において同等の高いパフォーマンスを示すことが明らかになりました。
ただし、このベンチマークはあくまで管理されたテスト環境での結果のため、実際の開発現場では採用しているワークフローやプロジェクトの要件によって最適な AI モデルが異なる場合があります。
開発者は一つの目安としてランキングを参照しつつ、自身の環境に合ったモデルを選択することが推奨されます。