

Z.aiが公開した新モデル「GLM-5.1」は、いわゆる単発のコード生成を競う段階から、長時間の自律実行でどこまで成果物を出せるかへと、評価軸そのものをずらそうとしている。公式ドキュメントでは、単一タスクを最大8時間にわたって継続し、計画、実行、テスト、修正、最適化までを回し切ることを中核価値として打ち出した。従来の「1ターンでどれだけ賢いか」ではなく、「長い作業をどこまで破綻せずにやり切れるか」を前面に出した構図だ。
同社はGLM-5.1を最新のフラッグシップモデルと位置づけ、コーディング性能はClaude Opus 4.6と全体として同水準、ただし長時間の自律タスクや複雑なエンジニアリング最適化ではより強い持続力を示すと説明している。200Kのコンテキスト長と128Kの最大出力、関数呼び出し、MCP、構造化出力など、エージェント構築を意識した機能群も揃えた。
焦点は、単に「高性能モデルが1つ増えた」という話ではない。GLM-5.1は、OpenAI系やAnthropic系の閉じた製品が強かったコーディング支援市場に対し、オープンウェイトと長時間自律実行を組み合わせて切り込んできた。しかもHugging FaceでMITライセンスのモデルとして公開しつつ、Z.aiのAPIとコーディング向けサブスクリプションの両方で展開する。モデル提供、開発者導線、料金、ローカル配備の選択肢まで一気に揃えたことで、単なる研究デモより一段実装寄りの発表になっている。
// 目次
まず見えるのは、コーディングとエージェント運用への明確な寄せ方
ベンチマークでの訴求点はSWE-Bench Pro
8時間連続実行の訴求は、単なる長文脈の話では片づけにくい
オープンウェイトと料金設定まで含めて、採用のハードルを下げに来た
市場への影響は、価格より選択肢の増加として表れそうだ
まず見えるのは、コーディングとエージェント運用への明確な寄せ方
公式のモデル概要ページによると、GLM-5.1は「long-horizon tasks」のために設計された最新旗艦モデルで、単一タスクを最大8時間、自律的かつ継続的に処理できるという。ここで強調されているのは、応答品質そのものより、長い作業の途中で方針がずれたり、エラーが積み上がったり、試行錯誤が空転したりしにくいことだ。これは、チャット応答の見栄えより、IDE内やCLI内で実際に作業を完走できるかを問うメッセージでもある。
同社はさらに、GLM-5.1がClaude CodeやOpenClawのようなAgentic Codingワークフロー向けに最適化されていると明記している。別ページの案内では、GLM Coding PlanのMax、Pro、Liteの全ユーザーがGLM-5.1を選択でき、Claude CodeやOpenClaw、Clineなどの外部ツールでもモデル切り替えや接続が可能だとしている。つまりZ.aiは、独自チャットUIの囲い込みではなく、既存の開発環境の中で「差し替え可能な主力モデル」としてGLM-5.1を置きに来たことになる。
この配置は重要だ。開発者がモデルを評価するとき、いまはベンチマークの点数だけでは決めにくい。実際には、CLIでの安定性、長い修正ループでの粘り、ツール呼び出しの雑さ、設定や課金の扱いやすさまで含めて判断される。GLM-5.1の公式説明は、その現実にかなり寄っている。単発のコード補完モデルというより、長い作業を預ける「作業エンジン」として売り出している印象だ。
ベンチマークでの訴求点はSWE-Bench Pro
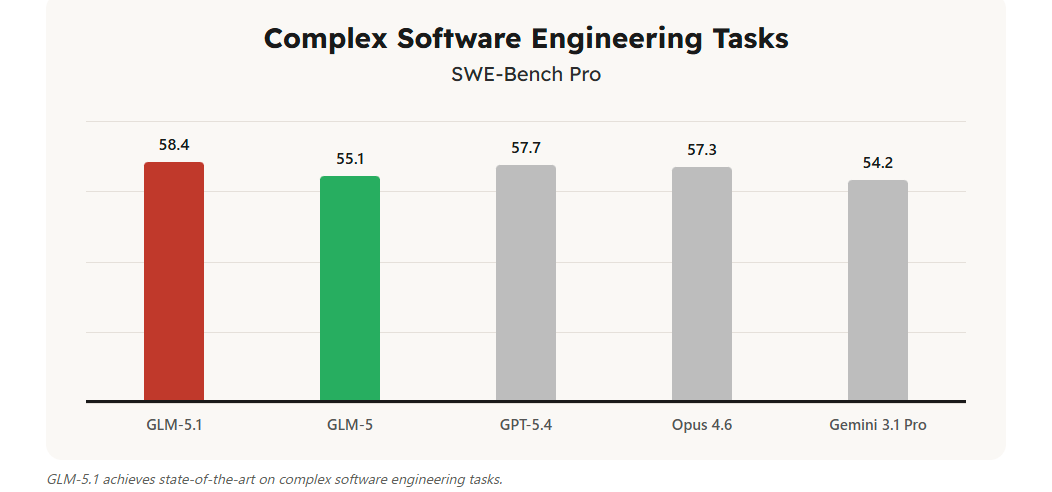
公式ドキュメントで最も強く打ち出されているのは、SWE-Bench Proで58.4を記録し、GPT-5.4、Claude Opus 4.6、Gemini 3.1 Proを上回ったという点だ。コーディングモデルの訴求としては分かりやすく、実務寄りの修正課題を使うベンチマークで先頭に立ったことは、少なくとも「コーディング専用の強さ」を説明する材料にはなる。
Hugging Face上の公式モデルカードを見ると、GLM-5.1はSWE-Bench Proで58.4、NL2Repoで42.7、Terminal-Bench 2.0で63.5を記録している。GLM-5比では、SWE-Bench Proが55.1から58.4、NL2Repoが35.9から42.7、Terminal-Bench 2.0が56.2から63.5へ伸びており、少なくとも同社が重視するコーディングとエージェント系の指標では、5.0系からかなり大きく押し上がったと読める。
ただし、この発表を「総合力で全面勝利」と読むのは早い。Hugging Faceの同じ表では、HLEやGPQA-Diamondのような指標でGemini 3.1 ProやClaude Opus 4.6、GPT-5.4が上回る項目も残っている。さらに、Terminal-Benchの一部は「Best self-reported」と明示されている。つまり、GLM-5.1の強さはかなり明確だが、それはとくにコーディング、ツール利用、長時間実行での伸びとして理解するのが自然で、万能首位と受け取るよりは「評価軸を絞るとかなり鋭い」という見方が妥当だろう。
この整理は、Z.ai自身の説明とも大きくずれない。公式ページでも「Claude Opus 4.6と全体として並ぶ」「複数の主要ベンチマークで先行する」といった書き方で、万能最強というより、グローバル上位群に並びつつ、長時間エージェント実行で差をつける構図を示している。分析として言えば、GLM-5.1の本当の価値は1回の賢い返答ではなく、試行回数の多い開発タスクでどれだけ途中失速しないかにある。
8時間連続実行の訴求は、単なる長文脈の話では片づけにくい
今回の発表で最も気になるのは、最大8時間の持続実行という主張だ。公式ページはこれを、長いコンテキスト長の話ではなく、目標整合性を維持しながら戦略のドリフトやエラー蓄積を抑え、複雑なエンジニアリング作業を閉ループで回せる能力だと説明する。ここは、近年のAIコーディング支援が抱えてきたボトルネックをかなり意識した表現になっている。
1回目の提案はうまく見えても、2回目、3回目、10回目の修正で崩れる。テスト結果を読み違え、同じ失敗を繰り返し、依存関係の副作用で全体を壊す。多くの開発者が感じてきたのは、まさにその点だった。GLM-5.1はそこに対し、モデルが実験し、結果を読み、ボトルネックを見つけ、方針を修正する「experiment-analyze-optimize」の反復を前面に出している。
公式には、8時間以内にLinuxデスクトップシステム全体をゼロから構築した例や、655回の反復でベクトルデータベースのクエリ性能を初期の本番版比6.9倍まで高めた例、KernelBench Level 3で3.6倍の幾何平均高速化を達成した例が示されている。もちろん、これらは同社が提示する代表事例であり、ユーザー環境でそのまま再現されると見るべきではない。それでも、モデルの売り方が「1ショットのコード生成」から「長い実験計画を走らせる主体」に変わっている点は見逃せない。

ここから先の競争軸も見えてくる。今後のコーディングモデル比較は、単純な生成品質だけでなく、長時間セッションの安定性、反復改善の歩留まり、ツール呼び出しの精度、作業完了までの人間介入量へと移っていく可能性が高い。GLM-5.1は、その変化をかなり早い段階で商品メッセージに織り込んだ。
オープンウェイトと料金設定まで含めて、採用のハードルを下げに来た
GLM-5.1はHugging FaceでMITライセンスとして公開され、SGLang、vLLM、xLLM、Transformers、KTransformersなど複数のフレームワークでローカル配備を案内している。巨大モデルである以上、誰でも手元で軽く回せる種類ではないが、少なくとも「重みは公開しつつ、APIとサブスクリプションでも使わせる」という配布戦略は明確だ。閉じたSaaSだけで囲うのではなく、導入経路を複数残している。
API料金もすでに公開済みで、Z.aiのPricingページではGLM-5.1の価格を入力100万トークンあたり1.4ドル、出力100万トークンあたり4.4ドルとしている。Cached Inputは0.26ドルで、Cached Input Storageは期間限定で無料だ。さらにCoding Plan向け案内では、Liteを含む全プランでGLM-5.1を利用可能としている。ここは、最先端寄りの性能を持つモデルを、比較的低摩擦に試させたいという意図が見える部分だ。
もっとも、採用がすぐ広がるかは別問題でもある。744B級の系譜を引く大型MoEモデルをローカルで本格運用するには、現実にはかなり重いインフラがいる。したがって短期的には、オープンウェイトであること自体より、APIやコーディングツール経由で「閉じた最上位モデルの代替候補」として試される展開のほうが現実的だろう。分析としては、GLM-5.1はオープンソース陣営の象徴的な勝利であると同時に、実務ではまずSaaS的に消費されるモデルでもある。
市場への影響は、価格より選択肢の増加として表れそうだ
GLM-5.1の発表が市場に与える圧力は、単純な「安い高性能モデルが出た」という話だけではない。より大きいのは、長時間エージェント実行に強いモデルが、米国勢のクローズドモデルだけの専売ではなくなりつつあることだ。とくにClaude CodeやClineのように、既存ツールの中でモデルを差し替えながら評価する文化が広がるほど、ユーザーはブランドより作業完了率でモデルを見るようになる。
その意味でGLM-5.1は、ベンチマーク首位の獲得以上に、「長い開発タスクを任せる候補が増えた」という事実のほうが市場には響きやすい。もし実利用で、数時間単位の修正、テスト、最適化、再実装を安定して回せるなら、モデルの勢力図はチャット品質ではなく、開発ワークフローへの食い込み方で塗り替わる。Z.aiはそこを狙っている。
一方で、現時点の情報だけで断定しにくい点もある。長時間自律実行の実力は、公開デモや自社評価だけでは見えにくく、実務では権限管理、環境差分、ツール失敗時の復旧、人間側レビューの負荷が結果を大きく左右する。したがって、今回の発表は「閉じた最上位モデルを完全に置き換えた」ではなく、「置き換え候補として本格的に比較対象に入った」と捉えるほうが現実に近い。
それでも、GLM-5.1が示した方向は明快だ。AIコーディング支援の競争は、短い応答の器用さから、長い作業を最後まで運べるかへ移り始めている。Z.aiはその転換点で、オープンウェイト、API、既存エージェント互換、そして長時間実行という4点を一度に押し出した。次に問われるのは、派手なベンチマークではなく、実際の開発現場で何時間ぶんの信用を獲得できるかだろう。
Sources