
を実装してみる | Llama3.1-8B – 半導体事業")
Llama3.1-8Bモデル利用の事前準備
Llama3.1-8Bモデルの利用権限リクエスト
今回はHugging faceのLlamaモデルをベースに、AI Hubを使ってオンデバイス推論用に最適化していきます。
Llamaモデルファミリーを利用するには、事前にHugging FaceのWebサイトで利用権限のリクエストが必要です。
初めてリクエストされる方は、こちらのページからお願いいたします。
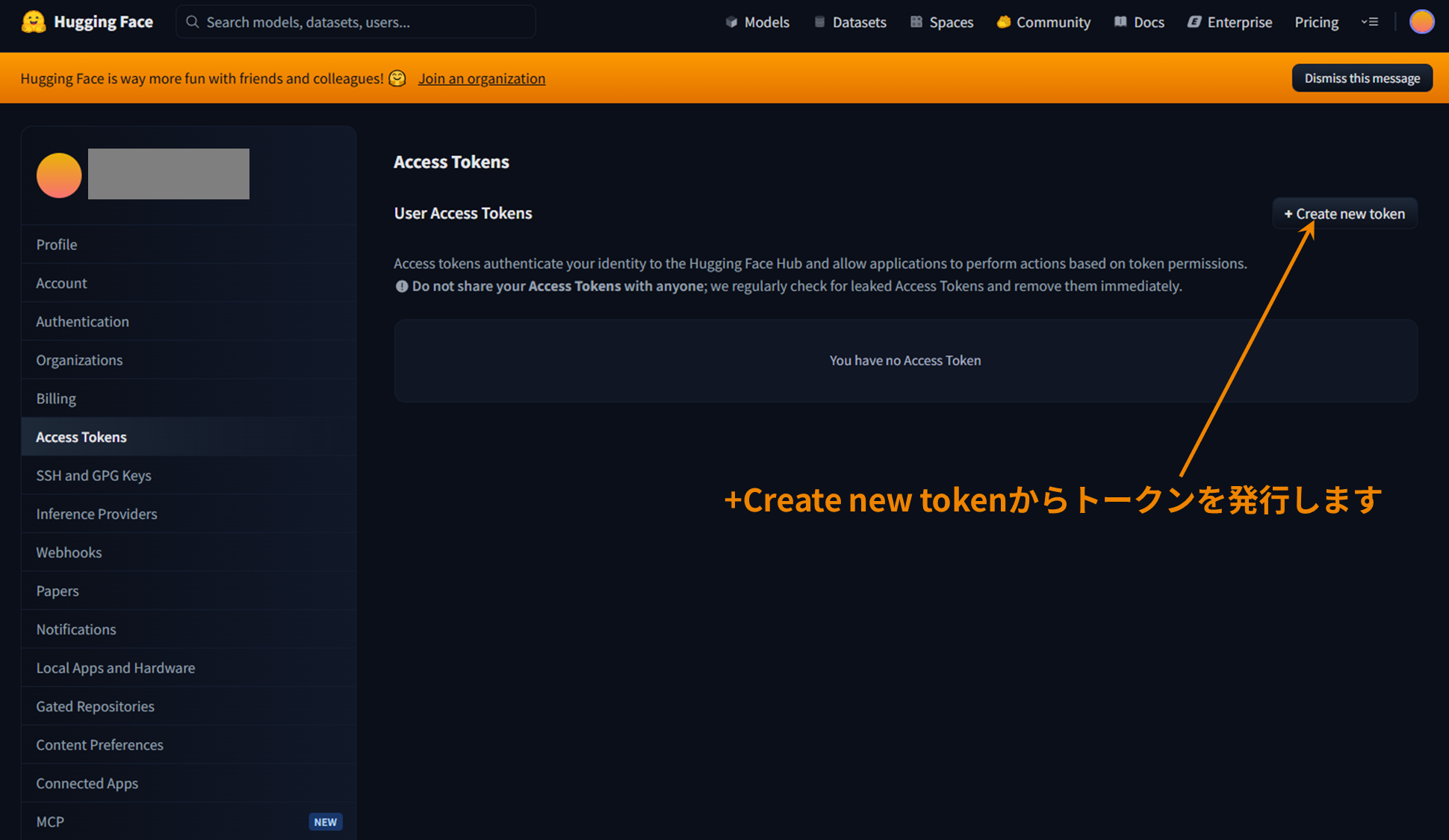
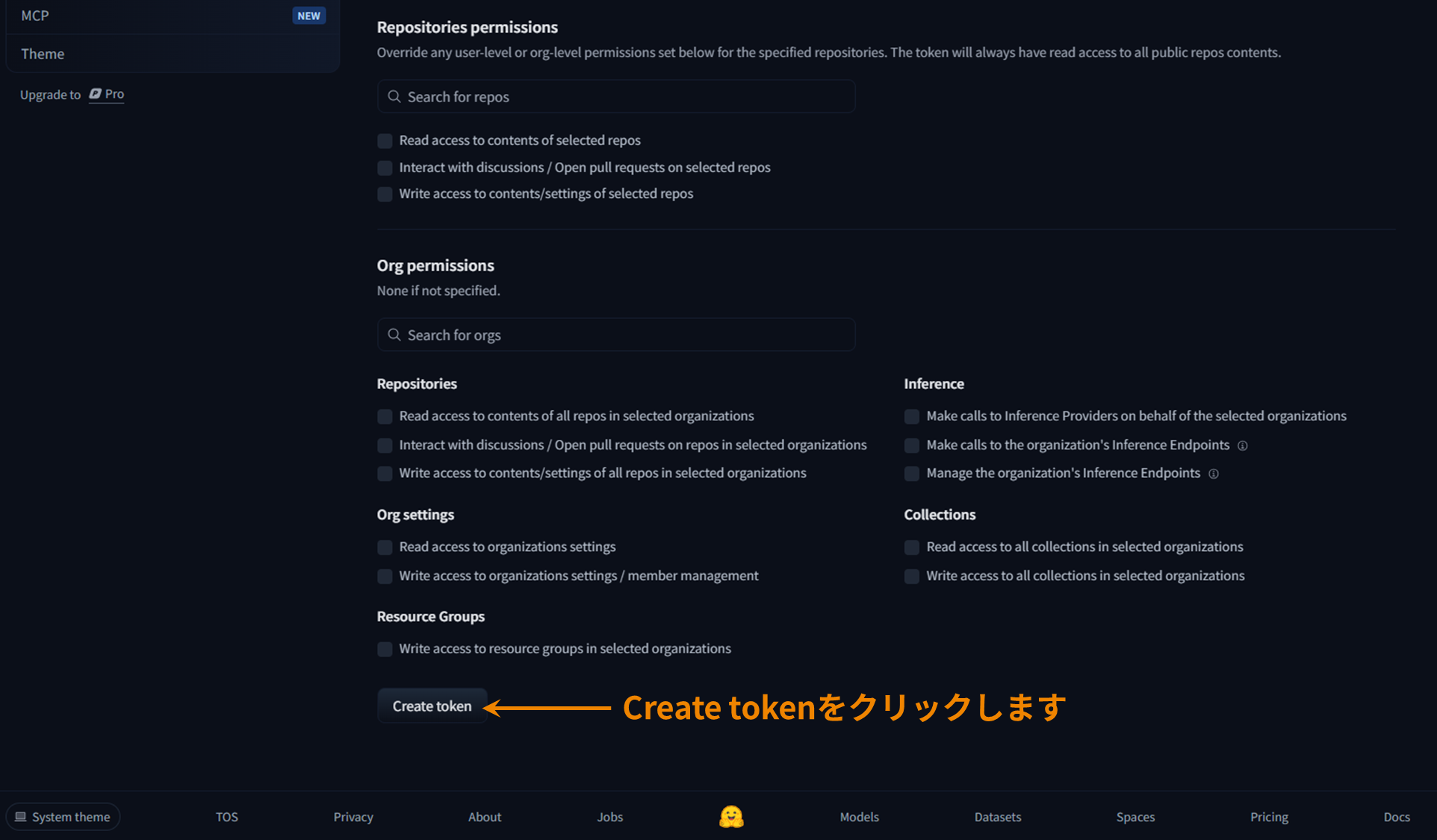
Hugging Faceアクセストークンの発行
利用権限の承認後にCLIからモデルにアクセスする際、Hugging Faceのアクセストークンを設定する必要があります。
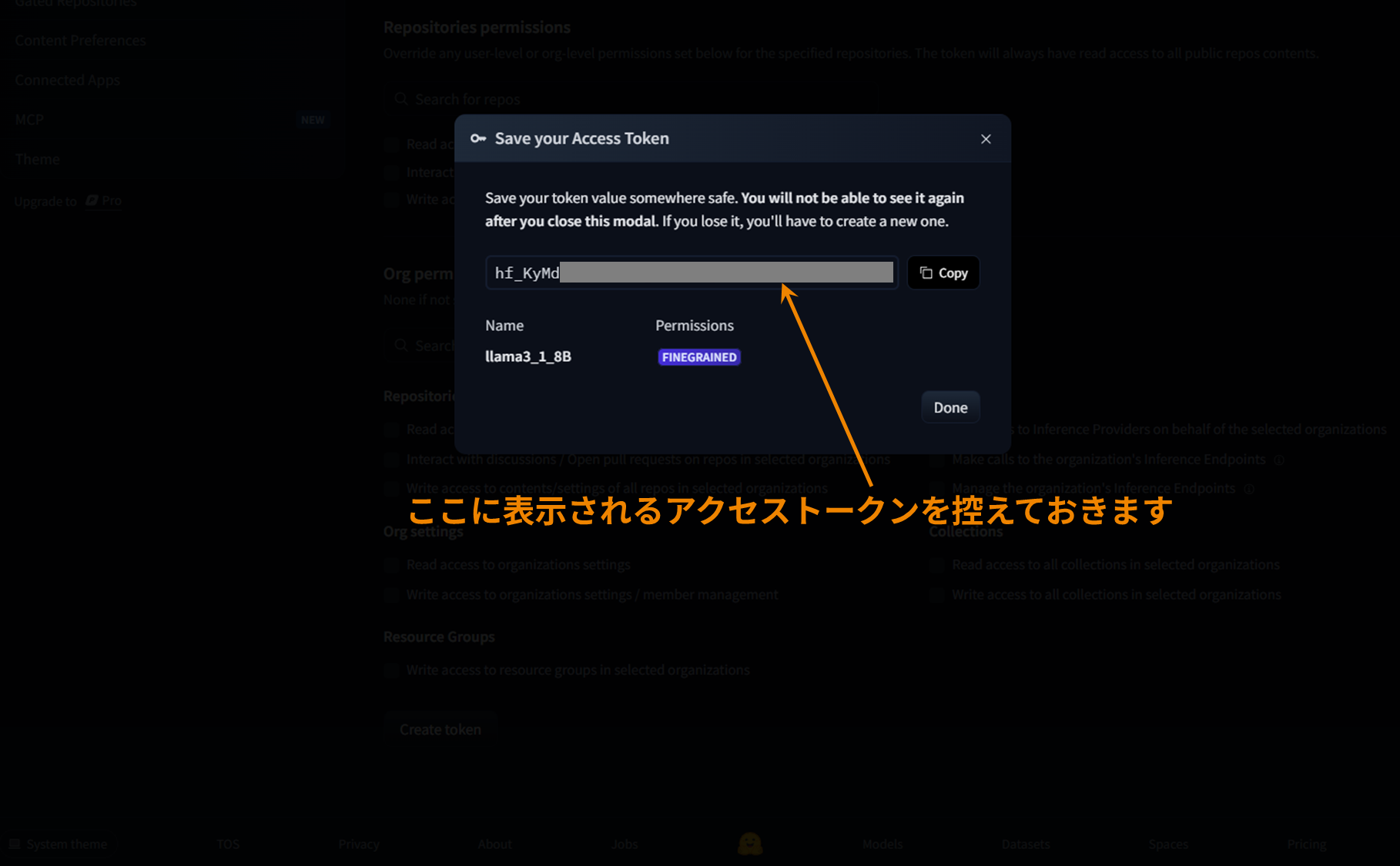
アクセストークンはこちらのページで事前に作成し控えておきます。
ホストPC環境構築
Qualcomm QAIRT SDKのダウンロード (v2.29以降推奨)
SDKはQualcomm Package Managerでダウンロードできます。ホストPCのUbuntu環境にSDKパッケージを配置してください。
本ページのデモではv2.33.0.250327を使用しています。
(補足)
Qualcomm Package Managerの使い方はこちらのページをご参照ください (メーカーのページへリンクしています)
仮想環境(venv)を作る
test@SDTEST:~$ python3 -m venv llama3_1_8B
test@SDTEST:~$ source llama3_1_8B/bin/activate
(llama3_1_8B) test@SDTEST:~$
QAIRT SDK環境の設定を行う
(llama3_1_8B) test@SDTEST:~$ source ~/qairtsdk/qairt/2.33.0.250327/bin/envsetup.sh
[INFO] AISW SDK environment set
[INFO] QNN_SDK_ROOT: /home/test/qairtsdk/qairt/2.33.0.250327
[INFO] SNPE_ROOT: /home/test/qairtsdk/qairt/2.33.0.250327
Llama3.1-8Bモデルを扱う際に必要なパッケージをインストールする
下記コマンドを実行することで必要なパッケージをまとめてインストールできます。
(llama3_1_8B) test@SDTEST:~$ pip install “qai-hub-models[llama-v3-1-8b-instruct]” torch==2.4.1 torchvision==0.19.1 aimet-onnx==2.6.0
Gitがインストールされていることの確認
(llama3_1_8B) test@SDTEST:~$ git –version
git version 2.34.1
メモリー容量の確認
メモリー(RAM Mem+Swap)は最低80GB確保しておく必要があります。確保できていないとモデルエクスポートの途中でエラーが発生します。
(llama3_1_8B) test@SDTEST:~$ free -h
total used free shared buff/cache available
Mem: 27Gi 528Mi 16Gi 1.0Mi 10Gi 26Gi
Swap: 60Gi 74Mi 59Gi
Hugging Face Hubのインストール
(llama3_1_8B) test@SDTEST:~$ pip install -U “huggingface_hub[cli]”
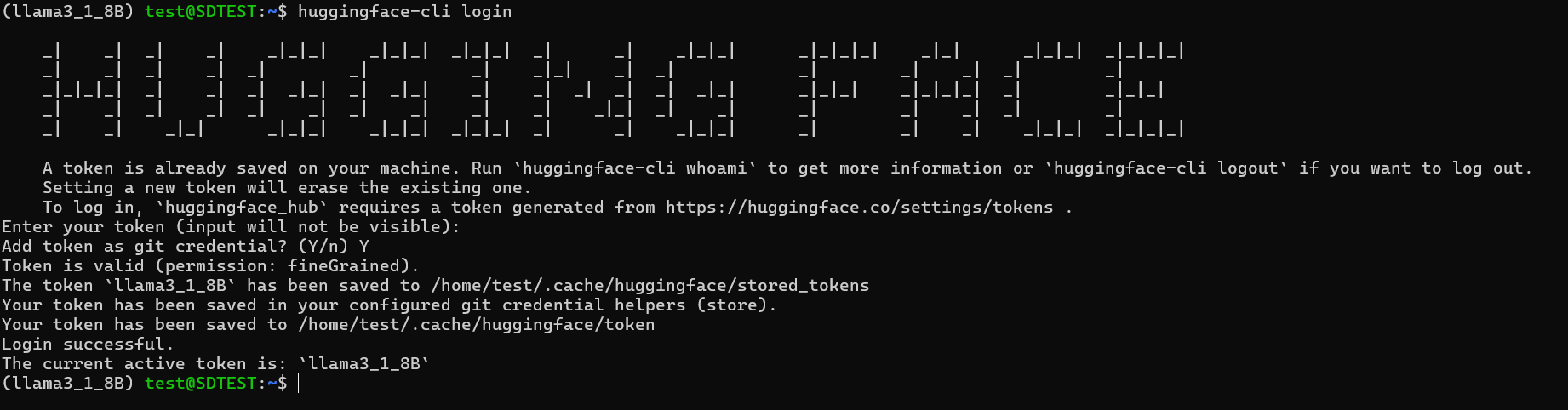
Hugging Face CLIにログイン
(llama3_1_8B) test@SDTEST:~$ huggingface-cli login
# Enter your token (input will not be visible): という表示が出るのでここに先ほど作成したアクセストークンを入力(ペースト可)します
ログインが成功すると下図のような出力になります。
Llama3.1-8Bモデルのエクスポート
AI Hub Modelsのエクスポート用コマンドを実行
このコマンドで下記のステップが自動的に実行されます。
・Hugging FaceからLlama3.1-8Bモデルの重みデータをダウンロード
・モデルデータのAI Hubへのアップロードおよびコンパイル
・コンパイル後のContext Binaryのダウンロード
(llama3_1_8B) $ python -m qai_hub_models.models.llama_v3_1_8b_instruct.export –device “QCS8550 (Proxy)” –skip-inferencing –skip-profiling –output-dir genie_bundle
実行完了すると”output_dir”に設定したディレクトリ(今回の場合はgenie_bundle)に、モデルに相当するContext Binaryファイルが生成されます。エッジデバイスで実行時に必要なメモリーサイズを考慮して、変換過程でモデルを5分割しているので、Context Binaryは5個生成されます。

エッジデバイス上でLLMアプリ実行
先述のContext Binaryとテキスト推論アプリ、各種ライブラリー、設定ファイルをエッジデバイスに転送し、アプリを実行します。
エッジデバイス転送するファイルは下記の通りです。先述のContext Binary以外のファイルの取得方法については弊社までお問い合わせください。
【Context Binary(モデル)】
llama_v3_1_8b_instruct_part_1_of_5.bin
llama_v3_1_8b_instruct_part_2_of_5.bin
llama_v3_1_8b_instruct_part_3_of_5.bin
llama_v3_1_8b_instruct_part_4_of_5.bin
llama_v3_1_8b_instruct_part_5_of_5.bin
【テキスト推論アプリ】
genie-t2t-run
【トークナイザー】
tokenizer.json
【コンフィグレーションファイル】
genie_config.json
htp_backend_ext_config.json
【ライブラリー】
libGenie.so
libQnnHtp.so
libQnnHtpNetRunExtensions.so
libQnnHtpPrepare.so
libQnnHtpV73Skel.so
libQnnHtpV73Stub.so
libQnnSystem.so
ファイルの転送が完了したらアプリを実行します。
genie-t2t-runはQualcomm社のSDKに含まれるテキスト推論アプリで、コンフィグレーションファイルと入力プロンプトを受け取り、レスポンスを返します。
LLMはモデルによって異なるフォーマットを持っており、各モデルから意味のある出力を得るためには、そのモデルに適したプロンプトのフォーマットを使用することが重要です。これは各モデルのHugging Faceリポジトリーで確認できます。例えば今回使用するLlama3.1-8Bモデルの場合、下記のようなフォーマットでプロンプトを入力します。
■プロンプトフォーマット
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
What is the capital of Japan?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
準備が整ったので推論アプリを実行します。実行の様子については動画でご紹介します。