

今回はFirefoxが持つAI機能の1つ、チャットボット、特にページの要約機能で使用するLLMをローカルLLMに変更する方法を紹介します。
FirefoxとLLM
1か月ほど前の2月3日に、FirefoxのAI機能を一元管理でブロック可能にという記事が公開されました。この記事ではFirefoxのAI機能が5つ紹介されていますが、少なくとも筆者が使用しているUbuntu 24.04.4 LTS上のsnap版Firefox 148では、AIチャットボットを除いて使い方がよくわかりません。
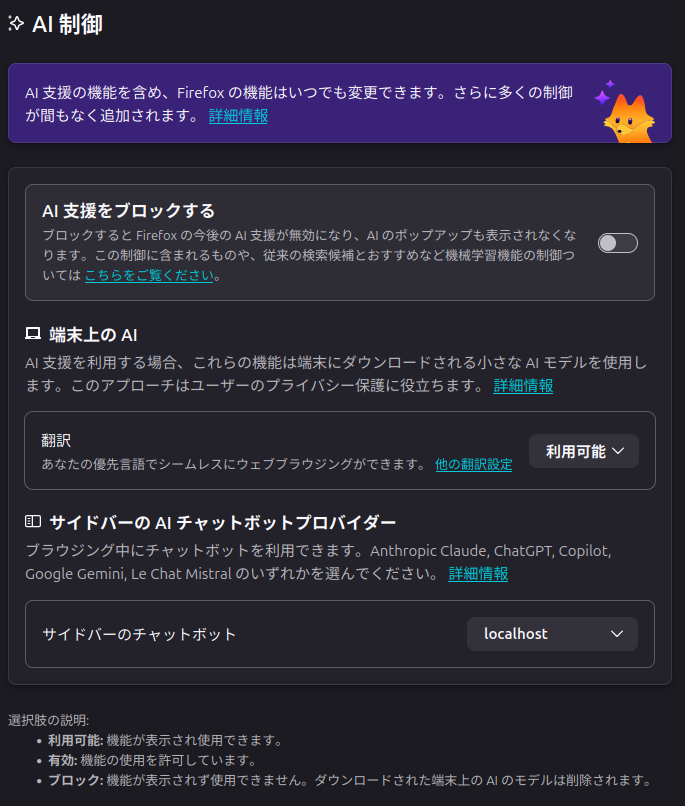
要約機能はAIチャットボット機能の1つで、本文中にもあるようにサイドバーから使用するLLMを選択して実行するものです。あとの機能はMozillaのブログ「Your data, your rules: Firefox’s privacy-first AI features you can trust」を読めばわかるのですが[1]、Firefoxが用意した独自モデルを使用するということのようです。そういわれて新設されたAI制御のメニューを見てみると、たしかにそのように分類されています(図1)。
[1] 厳密には英語の原文を読んだわけではなく、まさに今回紹介する方法を用いて要約させました。外国語の場合は和訳もしてくれるので便利です。
図1 Firefox 148に追加されたAI制御メニュー。ここではすでにlocalhostが有効になっているが
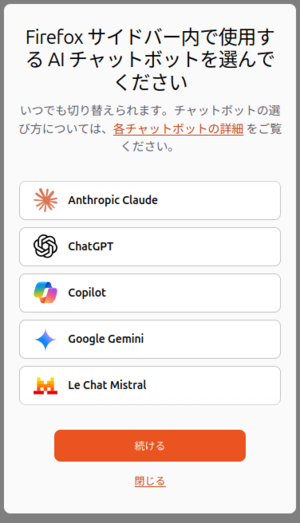
そしてサイドバーのAIチャットボットを開いてみると、大手のLLMサービスばかりでローカルLLMの選択肢はありません(図2)。はてさてどうしましょうか、というのが今回の記事となります。
図2 デフォルトではサイドバーのチャットボット機能にローカルLLMの選択肢がない
今回使用するPC
今回使用するPCのスペックは次のとおりです。
メーカー
型番
備考
CPU
Intel
Core-i5 13500
メモリー
Crucial
CT2K32G4DFD832A
64GB
マザーボード
ASRock
B760M Pro RS/D4 WiFi
CPUファン
ID-COOLING
IS-55-BLACK
グラフィックボード
玄人志向
RD-RX9060XT-E16GB/DF
VRAM 16GB
SSD
Crucial
CT500MX500SSD1
リムーバブルケース
Silver Stone
SST-FS202
電源ユニット
Silver Stone
SST-SX750-G
ケース
Silver Stone
SST-SG11B
諸般の事情で第891回とは替えています。
OSはもちろんUbuntu 24.04.4 LTSです。
ローカルLLMを動作させる
LLM
今回使用するRD-RX9060XT-E16GB/DFはVRAMが16GBです。がんばって大きなモデルを使用するのではなく、第891回のようにVRAMに収まるくらいのものにします。
真っ先に考慮すべきはgpt-oss-20bです。しかし、この記事にあるように2025年8月リリースで、今となってはやや古くなっています。gpt-ossを改変したGPT-OSS Swallowにするのも手です。というわけで、両方紹介します。
gpt-oss-20b
ggml-org/gpt-oss-20b-GGUFからダウンロードします(直リンク)。
GPT-OSS Swallow
公式には現在のところllama.cppで使える形式では配布されていません。実はそれはgpt-ossでも同じですが、信頼できるダウンロード元があります。しかし現状GPT-OSS Swallowにはなさそうに見えます。
そこで第872回でも紹介した、変換と量子化を行います。ストレージの空き容量を150GB程度確保した上で次のコマンドを実行してください。
$ sudo apt install -y git git-lfs libvulkan-dev glslc python3-pip python3-venv
$ mkdir ~/git
$ cd ~/git
$ git clone https://github.com/ggml-org/llama.cpp.git
$ cd llama.cpp
$ mkdir build
$ cmake -B build -DGGML_VULKAN=1
$ cmake –build build –config Release
$ cd ~/git
$ python3 -m venv ~/git/.gguf
$ source ~/git/.gguf/bin/activate
$ pip3 install -r ./llama.cpp/requirements.txt
$ git clone https://huggingface.co/tokyotech-llm/GPT-OSS-Swallow-20B-RL-v0.1
$ llama.cpp/convert_hf_to_gguf.py GPT-OSS-Swallow-20B-RL-v0.1/
$ llama.cpp/build/bin/llama-quantize ./GPT-OSS-Swallow-20B-RL-v0.1/GPT-OSS-Swallow-20B-RL-v0.1-BF16.gguf GPT-OSS-Swa
llow-20B-RL-v0.1/GPT-OSS-Swallow-20B-RL-v0.1-mxfp4.gguf MXFP4_MOE
これで~/git/GPT-OSS-Swallow-20B-RL-v0.1/GPT-OSS-Swallow-20B-RL-v0.1-mxfp4.ggufが生成されます。
llama.cpp
今回もモデルを動作させるインターフェースはllama.cppを使用します。前述のとおり自前でビルドできますが、ビルド済みバイナリもあります。
Releaseページの最新の「Ubuntu x64 (Vulkan)」をクリックすると、Vulkan向けのビルドがダウンロードできます。GPUがNVIDIAであってもAMDであってもIntelであっても対応します。
AMDユーザー向けには「Ubuntu x64 (ROCm 7.2)」でもいいのですが、sudo usermod -a -G render $LOGNAMEを実行して現在のユーザーをrenderグループに追加する必要があります。さらに再起動も必要です。ここまでしてインストールしても現状はVulkanのほうが速いため、わざわざ使用する理由はありません。
ダウンロードしたら適当なフォルダーに展開してください。
起動
llama.cppはたくさんのオプションがあり、モデルごとに変更する必要があります。よってこれから紹介するのはあくまで筆者普段実行している例です。
gpt-oss-20b
$ ./llama-server -m ~/Downloads/gpt-oss-20b-mxfp4.gguf –threads -1 –ctx-size 32768 –jinja -ngl 99 –flash-attn on –port 8080 –chat-template-kwargs ‘{“reasoning_effort”: “medium”}’ –temp 1.0 –top-p 1.0 –top-k 0.0 –no-mmap –fit on –no-warmup
GPT-OSS Swallow
$ ./llama-server -m ~/git/GPT-OSS-Swallow-20B-RL-v0.1/GPT-OSS-Swallow-20B-RL-v0.1-mxfp4.gguf –threads -1 –ctx-size 32768 –jinja -ngl 99 –flash-attn on –port 8080 –temp 0.6 –top-p 0.95 –top-k 20 –min-p 0 –no-mmap –fit on –no-warmup
注意
複数のVulkanデバイスが認識している場合、具体的にはiGPUとdGPU(グラフィックボード)が存在している場合には、llama-serverが起動中に強制終了する場合があります。そのような場合には–device Vulkan0オプションを追加して実行してください。
FirefoxのAI要約機能をローカルLLMで使用する
前置きが長すぎましたが、いよいよ本題です。
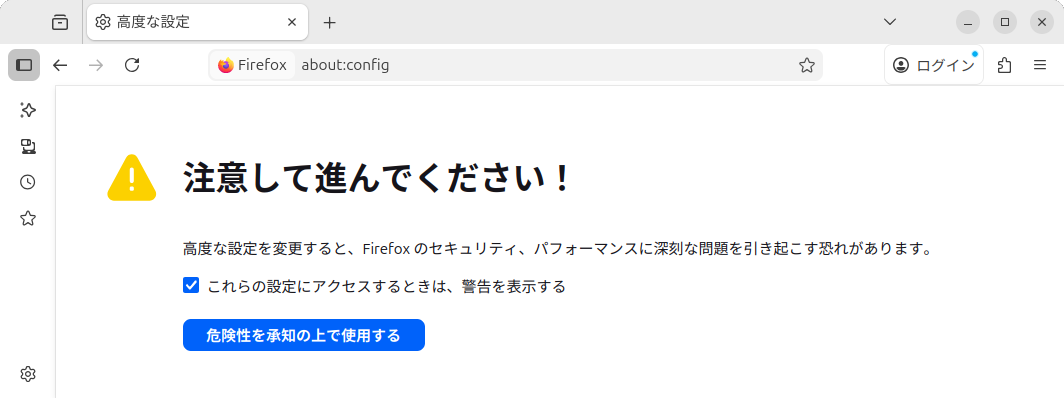
AIチャットボットによるローカルLLMはセキュリティの都合でデフォルトでは有効になっていないということで、URLの入力欄に「about:config」と入力し、「高度な設定」を開きます(図3)。「危険性を承知の上で使用する」をクリックします。
図3 高度な設定
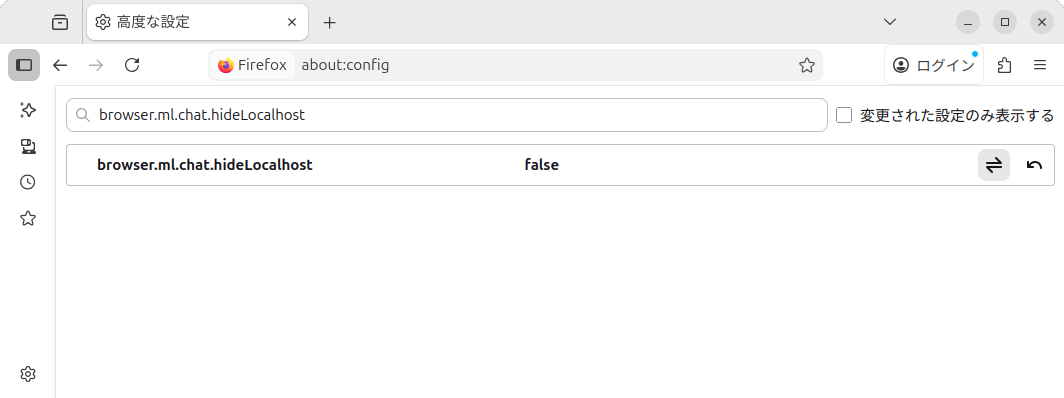
検索欄に「browser.ml.chat.hideLocalhost」と入力すると「true」になっているので、ここをダブルクリックして「false」にします(図4)。
図4 ここが今回のキモ
詳しくは紹介しませんが、「browser.md.chat.provider」でローカルLLMサーバーのURLを変更することもできます。どうしてもポートを8080にできない場合などに変更してください。また別PCのLLMサーバーにすることも可能ではあります。
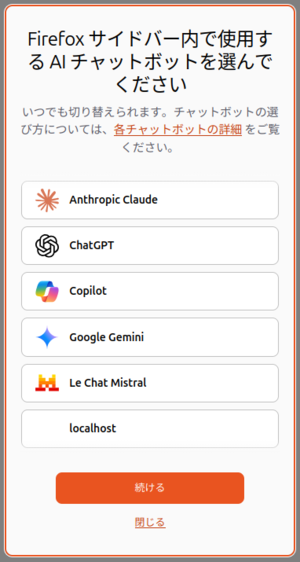
ここでサイドバーを開いてみると、AIチャットボットに「localhost」が追加されているので、選択して「続ける」をクリックします(図5)。
図5 AIチャットボットに「localhost」が表示される
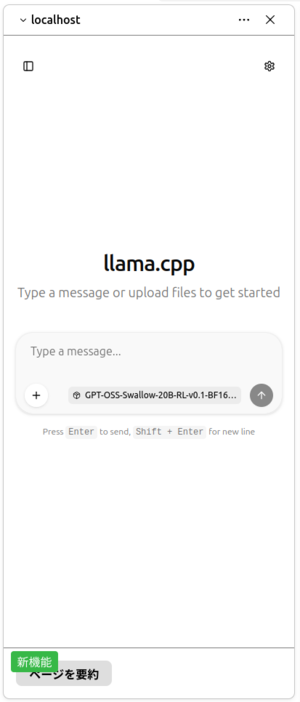
するとチャットボットが開き、左下に「ページを要約」があります(図6)。
図6 ローカルLLMが使用できている
ここをクリックすると、開いているページを要約してくれます(図7)。
図7 使用例
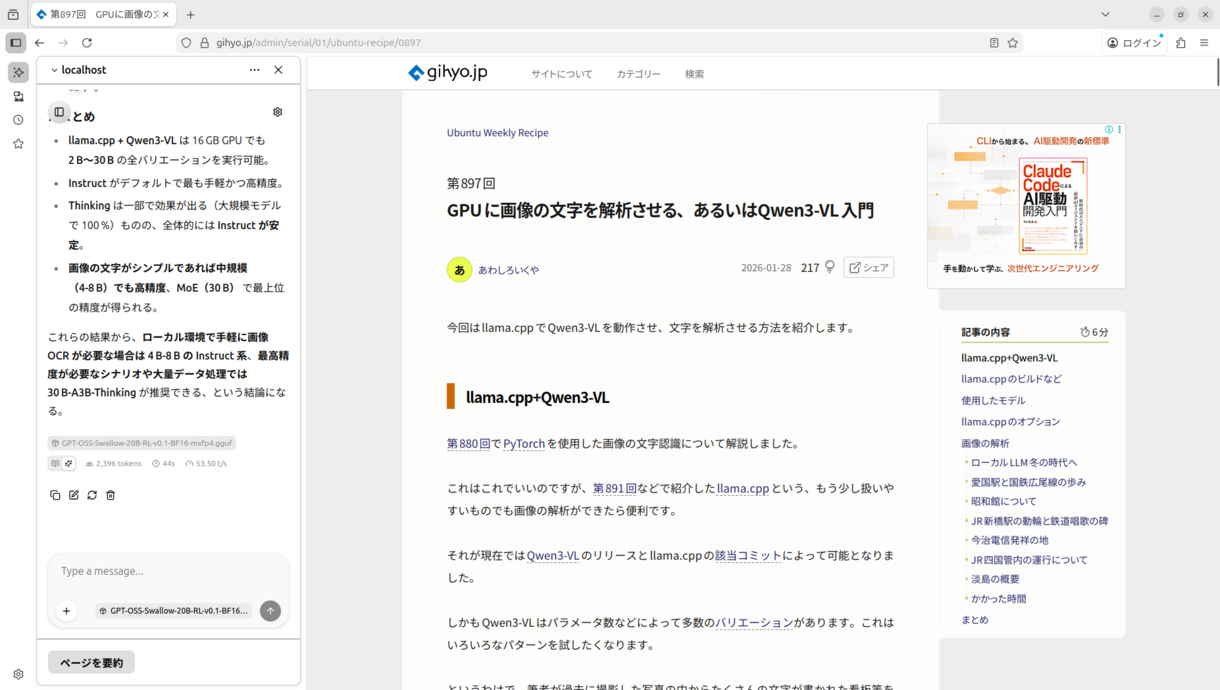
この記事も提出前に要約させ、趣旨と齟齬がないことを確認しています。またチェックもさせたら誤字を見つけてくれて助かりました。校正にも使えそうです。