
![第904回 ミドルレンジのグラフィックボードで生成AI入門[Intel編] | gihyo.jp](https://www.yayafa.com/wp-content/uploads/2026/04/ogp.jpg "第904回 ミドルレンジのグラフィックボードで生成AI入門[Intel編] | gihyo.jp")
今回は、グラフィックボードとしてミドルレンジのIntel Arc B580でllama.cppを使用する方法を紹介します。
ミドルレンジのグラフィックボードの現状
第891回で『ミドルレンジのグラフィックボードで生成AI入門』と題し、GeForce RTX 5060 TiとRadeon RX 9060 XTを紹介しました。
2026年3月中旬現在では、どちらも容易に入手可能です。しかし筆者が購入したGeForce RTX 5060 Ti(VENTUS 2X OC PLUS)は、2万円以上値上がりしているようです。やはりメモリーやストレージの価格高騰によりPCパーツ全般の売上が芳しくなく、価格の上昇や在庫の枯渇を招きにくい状況なのでしょうか。とはいえ2万円の価格差はなかなかに無視しがたいので、あの時点で購入したことは全く後悔していません。
現在はIntelもディスクリートGPU(dGPU)のメーカーです。そして、ミドルレンジと呼べるB580をリリースしています。そして、各社からそれを搭載したグラフィックボードもリリースされています。GeForce RTX 5060 TiやRadeon RX 9060 XTよりも安価でVRAMが12GBもあるので、手は出しやすいです。
しかし、やはりメジャーとはいえないのでいろいろな制限があり、それらと折り合いを付けてうまくやっていく必要があります。
今回は、そんな方法を紹介します。
IntelのdGPUとLLM
本連載では第747回と第866回でIntelのdGPUについて解説していますが、改めて紹介しましょう。
Intelの(21世紀に入ってからの)dGPU(Intel Arc)は第747回のA380や第866回のA580が第1世代で、今回使用するB580が第2世代です。現状第2世代のコンシューマー向けはB580しかリリースされていませんが、ワークステーション向けにはB50とB60がリリースされています。B70も計画されているようです。
GPGPUのソフトウェアスタック(Intelではツールキットと呼んでいる)としては、oneAPIとOpenVINOがあります。oneAPIはGPUで動作しますが、OpenVINOはGPUとNPUで動作するという違いがあります。oneAPIはdGPU用、OpenVINOはiGPU用ということでもなく、使い分けがちょっと難しいところではありますが、NPUを併用するかどうかが1つの基準になるでしょう。
第866回で紹介したIPEX-LLMも広い意味で捉えばそのうちの1つと考えられますが、残念ながら開発は終了しています。
llama.cppはSYCL(oneAPI)と、最近OpenVINOにも対応しましたが、今回はあくまでdGPU限定ということでSYCLを選択します。
最近Qwen 3.5が9BといったVRAMが少なくても動作するモデルをリリースしたのもB580の追い風になっています。
今回使用するPC
今回使用するPCのスペックは次のとおりです。
メーカー
型番
備考
CPU
Intel
Core-i5 13500
メモリー
Crucial
CT2K32G4DFD832A
64GB
マザーボード
ASRock
H670M-ITX/ax
CPUファン
ID-COOLING
IS-55-BLACK
グラフィックボード
ASRock
Intel Arc B580 Challenger 12GB OC
SSD
Crucial
CT500MX500SSD1
リムーバブルケース
Silver Stone
SST-FS202
電源ユニット
Silver Stone
SST-SX750-G
ケース
Silver Stone
SST-SG11B
B760M Pro RS/D4 WiFiのPCIeは4.0対応ですが、H670M-ITX/axはPCIe 5.0対応ということで入れ替えてみたものの、PCIe 5.0でリンクしているようには見えませんでした。UEFI BIOSの設定をいじったりはしてみたのですが。
OSはもちろんUbuntu 24.04.4 LTSです。
ドライバーのインストール
24.04.4のカーネル6.17はB580に対応しているので、ドライバーのインストールは必須ではありませんが、ここではドキュメントの内容を少々アレンジしてインストールします。次のコマンドを実行してください。
$ sudo add-apt-repository -y ppa:kobuk-team/intel-graphics
$ sudo apt-get install -y libze-intel-gpu1 libze1 intel-metrics-discovery intel-opencl-icd clinfo intel-gsc
$ sudo gpasswd -a ${USER} render
$ sudo gpasswd -a ${USER} video
$ newgrp render
$ newgrp video
oneAPIのインストール
続けてoneAPIをインストールします。次のコマンドを実行してください。
$ wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB | gpg –dearmor | sudo tee /usr/s
hare/keyrings/oneapi-archive-keyring.gpg > /dev/null
$ echo “deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main” | sud
o tee /etc/apt/sources.list.d/oneAPI.list
$ sudo apt update
$ sudo apt install intel-oneapi-base-toolkit intel-oneapi-runtime-libs
llama.cppのビルド
oneAPI(SYCL)用のllama.cppは簡単にビルドできます。次のコマンドを実行してください。
$ sudo apt install git cmake
$ mkdir ~/git
$ cd ~/git
$ git clone https://github.com/ggml-org/llama.cpp.git
$ cd llama.cpp
$ ./examples/sycl/build.sh
これで~/git/llama-cpp/build/bin以下に実行ファイルが作成されます。
比較のためVulkanバックエンドのバイナリもビルドします。次のコマンドを実行してください。
$ sudo apt install libvulkan-dev glslc
$ cmake -B build-vulkan -DGGML_VULKAN=1
$ cmake –build build-vulkan –config Release
これで~/git/llama-cpp/build-vulkan/bin以下に実行ファイルが作成されます。
使用するモデル
今回使用するのはDenseモデルとしては前出のQwen3.5-9Bとします。Q4_0で量子化したものがオススメです(Qwen3.5-9B-Q4_0.gguf)。
MoEモデルとしては、定番のgpt-oss-20bとします。こちらもQ4_0で量子化したものとします(gpt-oss-20b-Q4_0.gguf)。
DenseとMoEモデルの違いについては、こちらのコラムをご覧ください。
ベンチマーク
Qwen3.5-9Bのベンチマークを見てみましょう(図1)。
$ source /opt/intel/oneapi/setvars.sh
$ ~/git/llama.cpp/build/bin/llama-bench -m ~/Downloads/Qwen3.5-9B-Q4_0.gguf
$ ~/git/llama.cpp/build-vulkan/bin/llama-bench -m ~/Downloads/Qwen3.5-9B-Q4_0.gguf
図1 Qwen3.5-9Bのベンチマーク結果
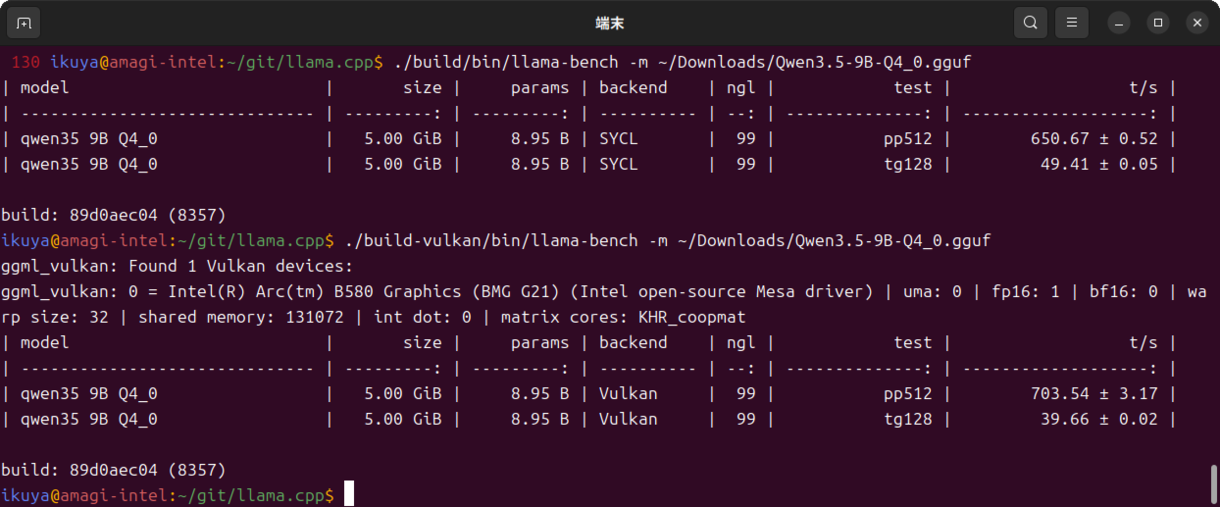
oneAPI(SYCL)のほうが速い、理想的な速度差となっています。
ではgpt-oss-20bではいかがでしょうか(図2)。
$ cd ~/git/llama.cpp/
$ source /opt/intel/oneapi/setvars.sh
$ ./build/bin/llama-bench -m ~/Downloads/gpt-oss-20b-Q4_0.gguf
$ ./build-vulkan/bin/llama-bench -m ~/Downloads/gpt-oss-20b-Q4_0.gguf
図2 gpt-oss-20bのベンチマーク
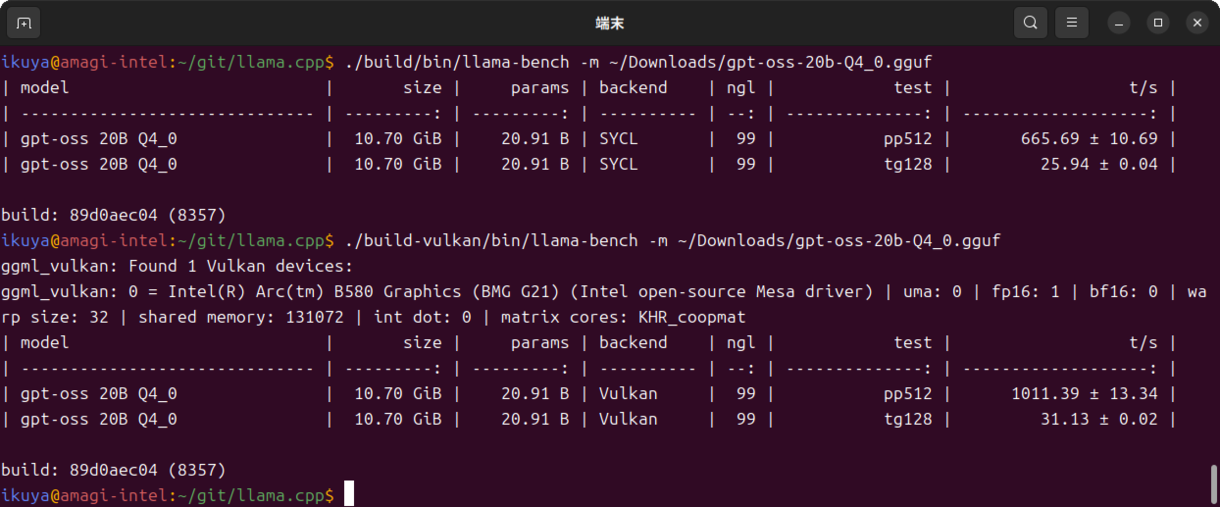
Vulkanのほうが速くなっています。これはVulkanのほうがMoEモデルの最適化が進んでいるということを意味しています(該当issue)。
実際の実行コマンド
実際の実行コマンドは、次を参考にしてください。
$ cd ~/git/llama.cpp/
$ source /opt/intel/oneapi/setvars.sh
$ ./build/bin/llama-server -m ~/Downloads/Qwen3.5-9B-Q4_0.gguf –ctx-size 16384 –port 8080 –temp 0.6 –top-p 0.95 –top-k 20 –min-p 0.00 –chat-template-kwargs ‘{“enable_thinking”:true}’
$ cd ~/git/llama.cpp/
$ ./build-vulkan/bin/llama-server -m ~/Downloads/gpt-oss-20b-Q4_0.gguf –ctx-size 16384 –jinja -ngl 99 –port 8080 –temp 1.0 –top-p 1.0 –top-k 0 –fit on
第902回の要約機能を両方のモデルで試してみましたが、SYCLでは少なくともgpt-oss-20bの動作は不安定だったので、Vulkanがおすすめです。またthinkingを有効にするとサーバーエラーが返ってきますが、作業自体は進んでいます(図3)。
図3 無視して閉じても構わないエラー
文字解析
第897回でQwen3-VLを使用して文字を解析させる方法を紹介しました。B580でももちろん有効です。またQwen3.5-9Bも文字解析に対応しており、追加でmmproj-F16.ggufが必要です。詳しくは第897回を参照してください。