

2026年03月26日 16時00分
AI
「ARC-AGI」はGoogleの元研究員でAIの研究を先導してきたフランソワ・ショレ氏が開発したAIベンチマークで、汎用人工知能(AGI)の実現に必要不可欠な「知能」の度合を測定できるとされています。「既存の知識を組み合わせて問題を解く能力」を測定する「ARC-AGI-1」、流動的知能の高低を測定できる「ARC-AGI-2」に続いて、「人間は100%のスコアを達成できるが、AIは1%未満しか達成できない」という「ARC-AGI-3」が2026年3月26日に発表されました。
ARC-AGI-3
https://arcprize.org/arc-agi/3
Announcing ARC-AGI-3
The only unsaturated agentic intelligence benchmark in the world
Humans score 100%, AI <1%
This human-AI gap demonstrates we do not yet have AGI
Most benchmarks test what models already know, ARC-AGI-3 tests how they learn pic.twitter.com/BC2QaNZuvH
— ARC Prize (@arcprize) 2026年3月25日
ARC-AGI-3は、AIエージェントが未知のデータにおいて適切な分類や予測を行う「汎化(はんか)」の能力を測定するために設計された、対話型推論ベンチマークです。従来のAIを評価する指標には静的なベンチマークが基準として用いられてきましたが、静的なベンチマークはLLMやAI推論システムの評価には有効である一方で、最先端のAIエージェントシステムを評価するには「探査」「知覚→計画→行動」「記憶」「目標達成」「アライメント」を測定できる新しいツールが必要です。
ARC-AGI-3は「人間がすぐに習得しやすい」「事前知識や隠されたプロンプトなし」「明確な目標設定と有意義なフィードバック」「力任せの暗記を防ぐ」という設計思想で構築されているため、100%のスコアを達成するためにはAIエージェントがそれぞれの環境内で経験から学習し、何が重要かを認識し、行動を選択し、自然言語による指示に頼ることなく戦略を適応させ、人間と同じくらい効率的にすべてのゲームをクリアできる必要があります。
公式ページでは、実際にARC-AGI-3で用いられるゲームをプレイすることが出来ます。以下は「wa30」というテスト。「START」をクリックしてゲームを開始します。
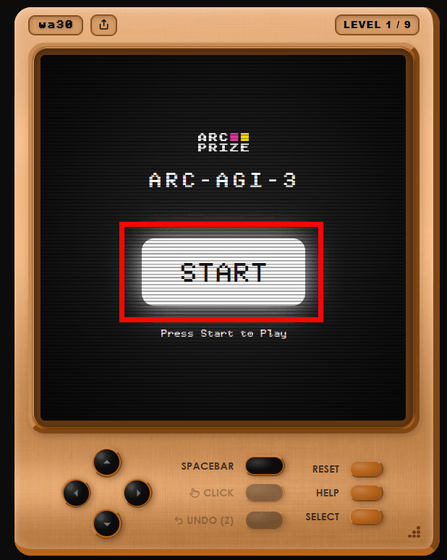
以下がゲーム画面。十字キーをクリックすることで緑の自機を動かすことができるほか、「SPACEBAR」をクリックして何らかの動作が可能です。キーボードの十字キーとスペースキーで操作することもできます。
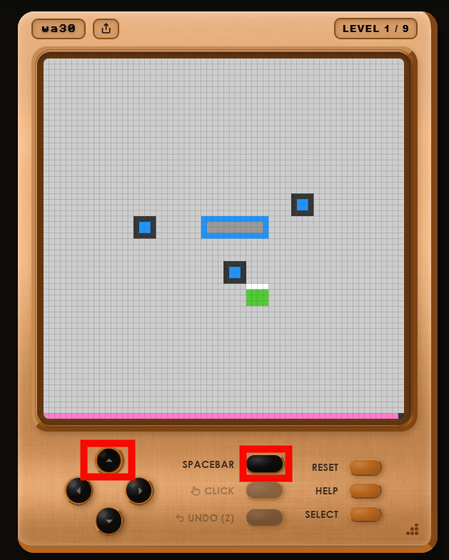
ゲームのルールは説明されないため、ボタンをポチポチ押しながら「緑色の四角が自機で、青色の四角の横でスペースキーを押すと黒枠が白枠に変化して移動可能になる」といったルールを把握する必要があります。
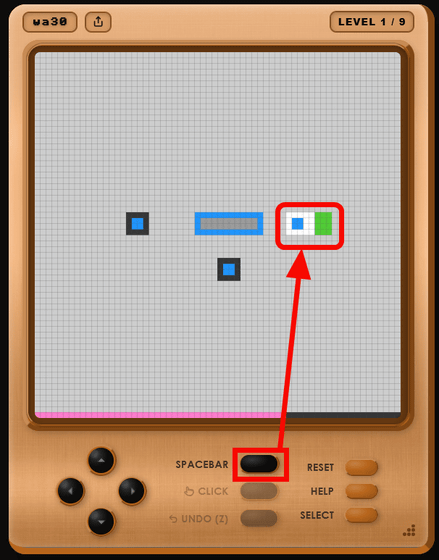
「中央に青色の四角が3個とも入りそうなエリアがあるから、そこに四角を移動させればクリアかも?」と推測してゲームを続行。
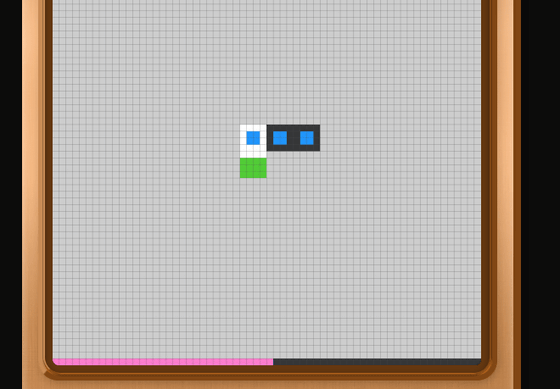
全ての四角を移動させたらステージクリアとなり、「LEVEL 2」が始まりました。新しいステージでは、新たに謎のオレンジ色の四角が登場しています。
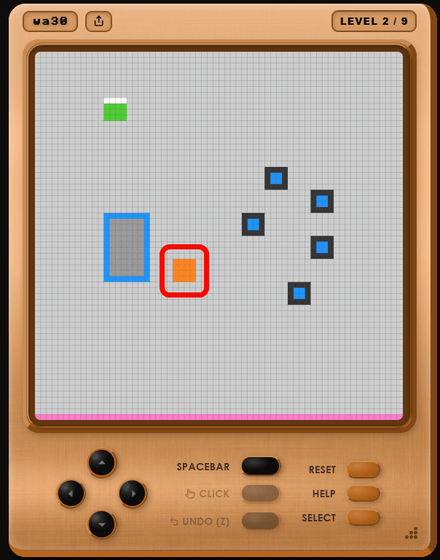
自機を動かしてみると、オレンジ色の四角は自動で動いて青色の四角を持ち運ぶ手伝いをしてくれるものだと分かりました。
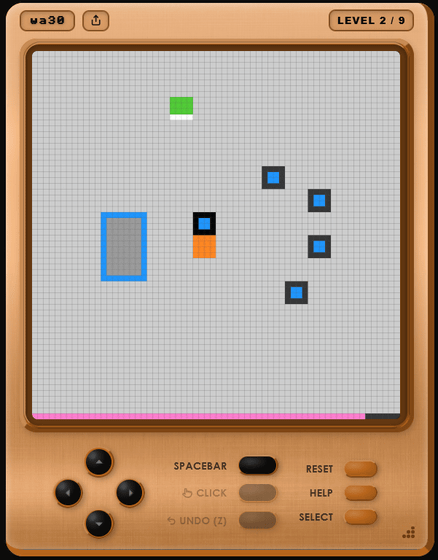
次のステージでは、真ん中が通過できない壁に分断されており、壁の向こう側にアイテムを集めるエリアと自動で動くオレンジ色の四角があります。このように、少しずつ手探りでルールを理解していって各ステージをクリアしていくのがARC-AGI-3のテスト内容というわけです。
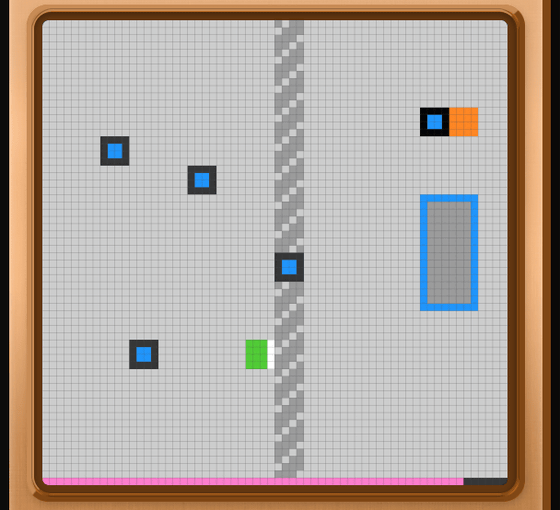
全ステージをクリアしたら「VICTORY!!」と表示されました。
ARC-AGI-3のデモとして遊べるゲームは複数あり、どれも即座にゲーム内容を理解できるものでした。しかし、AIエージェントはこのような「指示を与えられない中、ルールを理解してタスクをクリアする」ことを苦手としており、全てのゲームを人間は100%クリアできたにもかかわらず、AIはほとんどが0%、多くても2.78%とかなり低いスコアを記録しています。
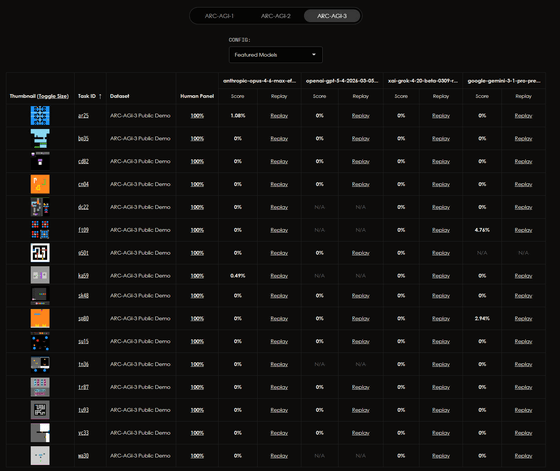
ショレ氏が共同で開催しているAGIを目指すプロジェクト「ARC Prize」によると、ARC-AGI-3における人間とAIのギャップは、AIがまだAGIにはほど遠いことを示しているそうです。ショレ氏は「知性とは、これまで見たことのない新しい物事やタスクをどれだけ効率的に理解できるかということです」と述べています。
一方でXユーザーのLisan al Gaib氏は、ARC-AGI-3のスコアについて問題点を複数指摘しています。例えば、人間の基準は「初回の挑戦で2番目に優秀だった人」の行動数で定義されており、一般的な人間ではなくある程度上位の成績が使用されています。さらに、スコアは「何問解けたか」ではなく「どれだけ効率よく解けたか」で評価されており、効率は二乗で計算されているため、「人間が10手で解いた問題をAIが100手で解いた」という場合にはどちらもクリアしていてもAIのスコアは「1%」と算出されています。これらのスコア基準によって人間とAIとで極端な差が生まれている可能性があります。また、人間の参加者には「十字キーとスペースで動かす」と伝えられるのにAIにはその知識も与えられないため、スコアは平等ではないとLisan al Gaib氏は指摘しています。
so you tell the people who wanted to participate (bias 1) that “you need to play the game to discover controls, rules and goal” (bias 2)
but the AI that has no interest or prior knowledge in ARC-AGI-3 puzzles isn’t told that it has to discover the controls, rules or the goal of… https://t.co/omm7Xvzf3J
— Lisan al Gaib (@scaling01) 2026年3月26日
また、Lisan al Gaib氏は「計算式の仕組み上、AIの性能がある程度に到達すると『AIのスコアが急激に伸びた』ようなグラフが形成される」とも指摘しています。
my prediction is that the benchmark will be mostly useless and will miss most progress in 2026
only at the end of 2026 or in 2027 will we see scores ramp up from like 20 to 80% within a few months
right now all but 3 models score literally 0 and the scores are meaningless.… https://t.co/KRvTHLeVI4
— Lisan al Gaib (@scaling01) March 25, 2026
ただし、ソーシャルニュースサイトのHacker NewsでLisan al Gaib氏の指摘が取り上げられた際には、「AGIを目指すなら平均的な人間ではなく優秀な人間を基準にするのは理にかなっている」と反論されています。また、ショレ氏もスレッドに登場しており、人間のスコアが極端に高いものではないことや、評価の仕組みやプロンプトをシンプルにしているのはより汎用的なAIの能力を測るためだと説明しています。
この記事のタイトルとURLをコピーする